Research Assistant Mark Turner explains his thoughts behind the design of the Cutting Edge website.
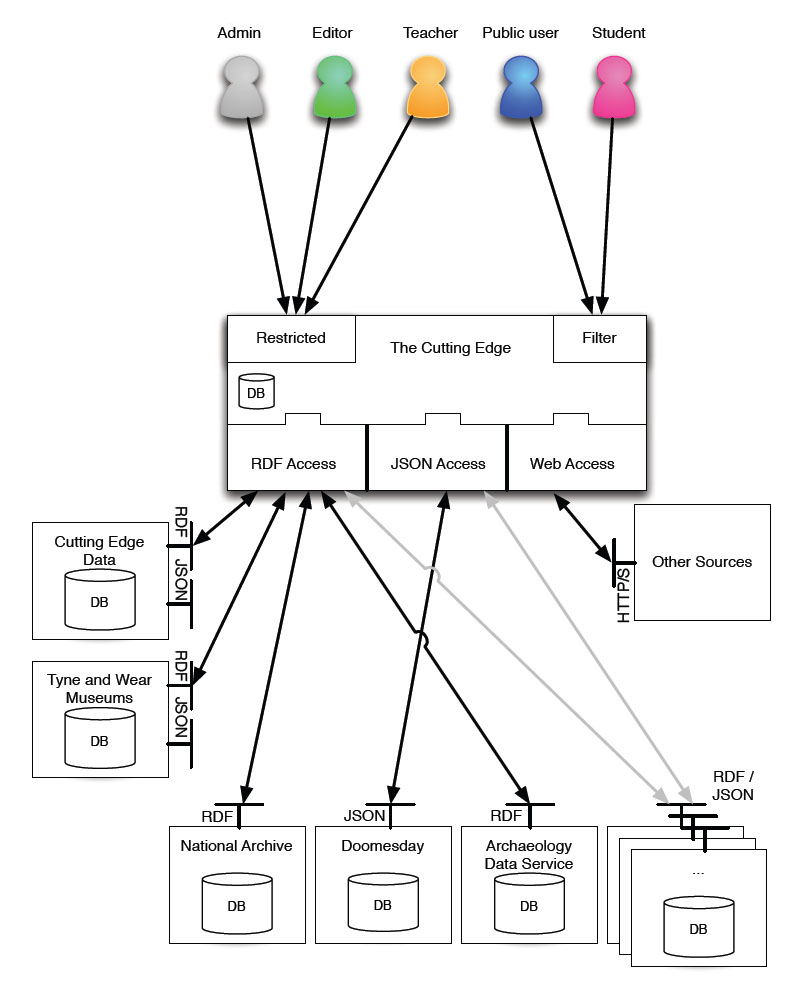
When designing the architecture for a system for a problem which the Cutting Edge project is trying to solve, it is important to keep the solution as general and flexible as possible. This generalisation is what enables the system to scale easily, being able to incorporate new requirements and integrate them as seamlessly as possible. In this instance the idea was not to not think about the information the Cutting Edge database actually contains, only that there is some data. Similarly with the users, the exact types and privileges of each role are not important, only that those roles exist.
To allow for multiple data sources, some outside the control of the project, it was decided to introduce a level of abstraction between the Cutting Edge website and the database. By treating the Cutting Edge database like any other data source consumed by the system, it allows the website to be built in a block-like manner, with no need to make the Cutting Edge database some kind of special case or precedent.
In actual fact the website has no notion of there being a database; it only knows that there is a web service which returns Cutting Edge data. This abstraction allows for future changes to be made to the Cutting Edge data store without the need for major work on the website. The type of database could be changed completely and the web site might never need to be changed. The social network Twitter works in this way. It has an Application Programming Interface (API), which it allows other people to use and develop their applications on top of. Twitter simply treats itself like any other developer and effectively uses its own API for its website and mobile apps.
Figure 1 shows the final architecture for the Cutting Edge system. This type of architecture has allowed the introduction of other third party data sources with minimal modifications to the architecture. Third party data sources such as the Archaeological Data Service and The National Archives are treated the same way the Cutting Edge data is, using much of the same application code. This commonality is what makes the system highly scalable, more and more third party data sources can be added over time without the need for the system to be heavily modified each time.