
As part of Geospatial Engineering’s on going involvement in the Infrastructure Transitions Research Consortium (ITRC – www.itrc.org.uk), various network models of infrastructure networks have been developed. This has involved the development of a custom database schema within PostGIS to handle networks created within the Python package, networkx. The linkage architecture has been provided by a custom built set of Python modules allowing raw line and point data within PostGIS to be fed into networkx.
Each network is represented within PostGIS as a series of three tables; a table representing nodes, a table representing the edges within a network and their attributes, and finally a table representing the geometry of the edges. A series of node, edge and edge geometry parent tables within the custom database schema are inherited from when a specific network instance is written to the database. The inheritance from these parent tables ensures a minimum set of columns are transferred to each instance table for each network, with a series of foreign key constraints applied to enforce referential integrity within the database. These foreign key constraints for example, ensure that an edge can only exist within a network provided that the nodes at either end of that edge also exist.
The attributes of each edge created are transferred from the attributes supplied within the raw line data. If no point data is supplied to the network build functions, then nodes are created at the end of each linestring, with blank attribute values. Alternatively if a set of points are supplied, then these attributes are copied through to the node table. Each node and edges created within networkx are written to each table individually, where checks are made against each node and edge table to check if a node or edge with the same geometry has already been created. This check is performed using the ST_Equals function available within PostGIS.
To enhance performance of the Python network writing module that is used to write networkx network instances to PostGIS, a version of the writing functions has been created exploiting the PostgreSQL COPY function. Prior to writing the data to the PostGIS database each node, edge and edge geometry table is created as a CSV file, with the COPY function used to bulk write the data to the database. Furthermore, this second approach to writing the networks to the database does not require multiple read/writes to check if a node or edge already exists i.e. stored, as this is handled within memory.
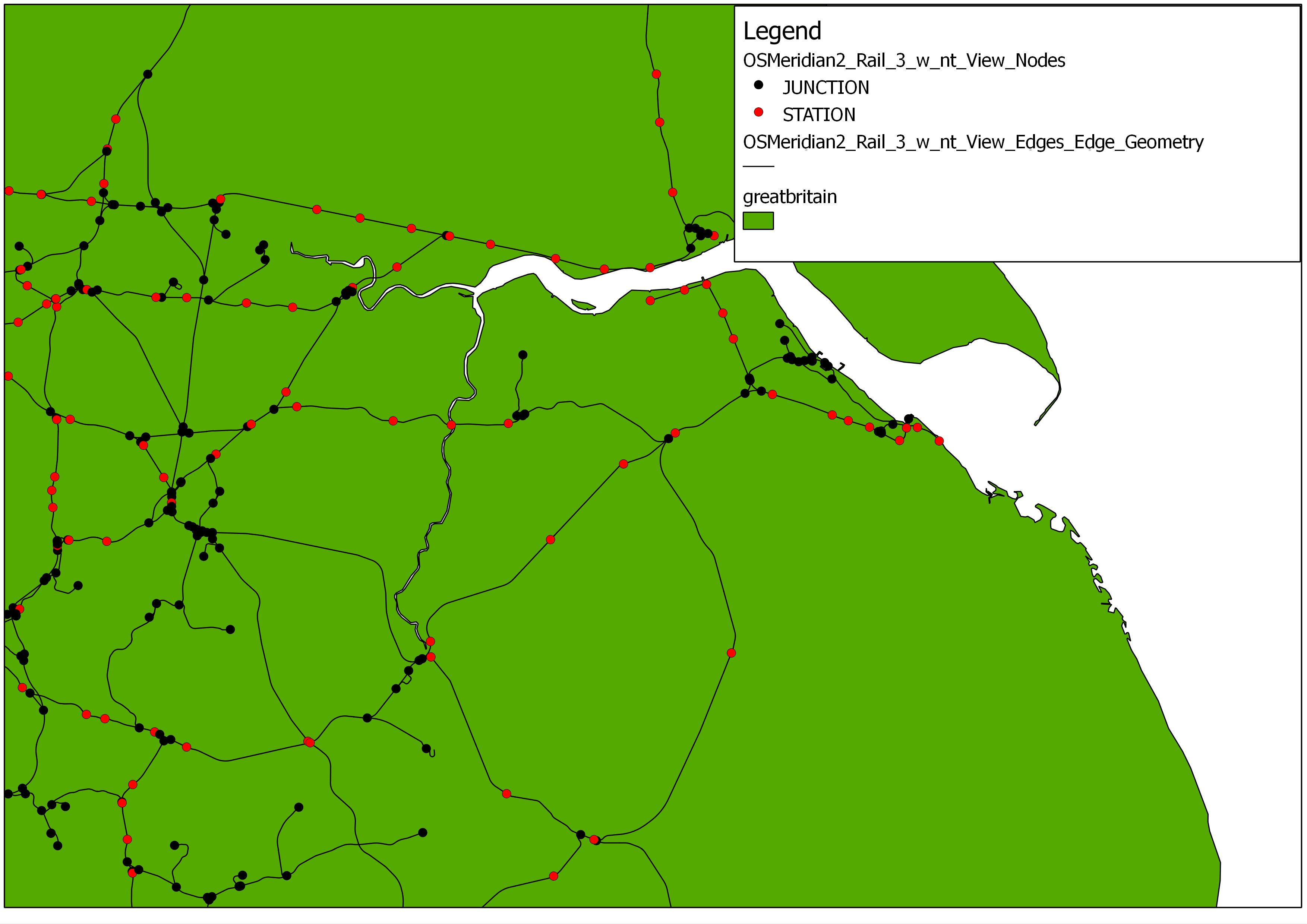
The Ordnance Survey Meridian 2 Rail data has created as a spatial and topological network within the database schema, using the Python linking architecture between PostGIS and networkx. Initially a table of rail ‘junctions’ was created offline by calculating the number of intersecting lines at each vertex within the raw data. This data table was used as the point input table, whereby a “type” attribute for each node with a value of ‘junction’ was defined.
Utilising the writing functions whereby a network edge and node is written individually to the database for each within the network, the network was built from the raw data, and then written to the PostGIS database within 5 minutes. This network contained:
- 7995 nodes (1416 JUNCTIONS)
- 8484 edges
Utilising the CSV writing functions whereby a CSV version of the Meridian Nodes, Meridian Edges and Meridian Edge Geometry are created prior to bulk writing these to the database, reduced the network build and write time, for the same number of nodes and edges as discussed previously, from approximately 5 minutes to less than 30 seconds. Furthermore the CSV representation of the Meridian Rail network, based on the level of attribution available from the raw data plus the newly-defined “type” attribute to store the ‘junction’ value, are only 5Mb in size, making this easy to share with others.
Further comparison of the two approaches to writing the network data to PostGIS, utilising the Ordnance Survey Meridian 2 Road (A, B, Motorway) data shows a similar improvement in writing performance if the PostgreSQL CSV COPY approach is used. For an area in North West England (covering approximately 22,000km2), containing a total of 291759 raw input points (taken from the road_node and rndabout for A, B, and Motorways only), and 46836 input lines (combining A, B and Motorways for the chosen North West region), it was possible to reduce the network build and write time from approximately 61 minutes to 17 minutes 25 seconds.
The image below shows a portion of the Meridian Road Network (A, B, Motorway) for the North West of England

I’ve been trying to do this for some time – are you able to share your scripts?