Derided by Word’s grammar check, much loved by politicians, acquired late by children and processed slower than the alternative even by adults – the passive voice was put in the spotlight by the 2014 National Curriculum reforms and is considered a source of strife by primary teachers up and down England and Wales. But what is known by kids, and for that matter adults, about the passive voice?*
Hold on a second. What is “voice”?
Voice is a grammatical tool for marking the relationship between the verb and what we call ‘arguments’, phrases that the verb needs to be able to fully express its meaning. Here are a few examples of verbs and their arguments:
(1) I ran. (I = argument, ran = verb) (2) I ate the cake. (I, the cake = arguments, ate = verb) (3) I gave the present to my friend. (I, the present, to my friend = arguments, gave = verb)
All of the examples in (1-3) are in the active voice. This means that the agent of the verb – the ‘doer’, in all these cases – is the subject of the sentence.
What’s a subject?
If we’re totally honest, no-one has a good definition, and it’s not clear if ‘subject’ is a useful concept for all human languages anyway. But for our purposes, the subject is the argument that precedes the verb in active, declarative sentences in English (those that tend to express statements). If a subject is a pronoun, it looks like “I, he, she, they, we” rather than “me, him, her, them, us”.**
So what is the passive voice?
In English grammar, there’s an option to make other arguments, not just agents, the subject of the sentence (assuming there are other arguments to choose from!). This is called the passive voice, which you can see in (4-6), corresponding to (2-3):
(4) The cake was eaten by me. (5) The present was given to my friend by me. (6) My friend was given the present by me.***
In (4) and (5), the ‘theme’ or ‘patient’ arguments are made into the subject of the sentence (preceding the verb), and the agent argument, I is taken away and tagged on to the sentence as part of the phrase by me.**** In (6), the ‘recipient’ argument becomes the subject, and again, subject I has to make way.
This creates an alternation. The exact same event – for example, my eating a cake – can be expressed in two different ways grammatically. And you’ll notice that the passive voice has more grammatical machinery in it than the active voice does. So while I’m thinking about cake, let’s whip up a recipe for making the passive voice!
A recipe for the passive voice
Ingredients: 1 active sentence (with at least two arguments) 1 auxiliary verb be 1 passive participle ending -ed Optional: 1 preposition by
Recipe
Take your active sentence, e.g. Molly bakes a cake, and identify the arguments. Once you’ve found the agent, here Molly, chop it off and put it to one side for later.
Now find the theme, here the cake. Chop that off too, and stick it onto the front of the sentence to make the cake bakes.***** Now, the cake is the subject of your sentence.
Take your auxiliary verb be and mould it into the same tense as in your original sentence. Our original sentence was in present tense, so we need a form like am, are, is. We pick the one that matches the new subject the cake, so we choose is.
Pop your auxiliary is in between the new subject and the verb, to make the cake is bakes. Don’t worry if this looks a bit funny – we haven’t finished yet!
Chop any tense off your main verb bakes. Tense is now marked by your auxiliary is, so you don’t need it twice! Here, we chop off -s to make bake, and our whole sentence looks like the cake is bake.
Take your passive participle ending -ed and pop it onto the end of your main verb bake. Now you should have the cake is baked.
Hooray! You can stop at this point and you have a beautiful passive sentence, known as a “short” passive. But you can add in your optional extras in another step…
7. Take your preposition by, and the agent that you put to the side earlier, Molly. Stick these two together and pop them on the end of your short passive to make a long one: the cake was baked by Molly.
Other cooking notes
You may have noticed that the recipe doesn’t work so neatly for irregular verbs like ‘eat’. In this case, you need to put on irregular participle ending ‘-en’, to take you from Molly eats the cake to The cake is eaten by Molly. But everything else stays the same. For other irregular verbs, the form might be a bit different, like bought for buy.
You’ve got another option if you’re a Tyneside English speaker too. On Tyneside, you don’t have to use the participle form of a verb in the passive – you can just use the past tense (also known as the preterite) form. So Tyneside English speakers might say The cake is ate by Molly.****** See if your local dialect can also spice up the passive just like Tyneside English!
So you mentioned that kids acquire the passive late…
Indeed I did, and considering all the grammatical machinery laid out above, you can start to see why children don’t correctly understand some English passives until the age of 6.
However, work by my superb colleague Dr Emma Nguyen has shown that it’s not just about frequency of passives in the input – the verb also plays a big role in acquiring the passive. She showed that children understand earlier passives that contain certain verbs – namely those that express actions that are intentional and where the agent has a physical effect on the theme, like wash and fix. Passives using these verbs can be understood around the age of 3.
In contrast, children are latest to acquire the passive with verbs that express states of being where the agent experiences a feeling for the theme, like love and believe. Adult-like understanding of these verbs only develops around age 6. Emma suggests that children learn about the different types of events that verbs can express, then use that knowledge, along with their syntactic knowledge, to gradually expand their understanding of the passive voice.
I’m a teacher and I’m supposed to teach the passive voice to children aged around 9…
So, that is kind of rough on you (not to mention them) given that they’ve only had a couple of years of successfully interpreting passive sentences at this point. You can tell that the 2014 curriculum reformers didn’t consult acquisitionists!
What I’d advise here is making sure that your students know first all the key concepts that feed into the passive voice, e.g. auxiliary verbs, concepts of agent and theme, subject and object, and about verb endings, because as the recipe shows, you can’t really talk about constructing the passives without being able to identify your ingredients.
I’m also a big advocate for making grammar learning as much like a scientific adventure as possible. Children love spotting examples, matching patterns, using magnifying glasses and chopping things into pieces. I think you can do all of these things with language too, both “in the wild” and in controlled ways in the classroom.
I also think that grammar teaching is much more fun and engaging when variation is taken into account – that’s to say how structures look and sound different in different dialects and in different languages (see the Tyneside English cooking note). It’s true that taking non-standard English into account takes a lot of courage and confidence from you as a teacher, but if you can do it, there’s a 2-fer-1 to be had – interesting takes on a theme and validation of other ways of speaking that will make your students feel heard.
If you want a bit more support too, I’m going to put in a plug for a fabulous free resource from linguist colleagues at UCL – the Englicious site. Friendly explainers for non-linguists, lesson resources, and CPD days, it’s a great resource to have in the back pocket.
Notes
*If you spotted my little metalinguistic joke in the title and first paragraph…I’m sorry. I could not be helped by myself.
**Why no “it, you, that”? Because they look the same whether they are subjects or objects, and so wouldn’t make my point very clear here! If you want to know more about why pronouns look different in subject and object position, read up on grammatical case.
***Not all dialects of English allow examples like (6), so you might not find this grammatical. But my fabulously flexible North West England dialect allows it, so I’m including it, and you can’t make me do otherwise 😉
****Notice that “I” becomes “me” after ‘by’ because it’s not the subject any more. It’s all about case again!
***** “The cake bakes” isn’t such a bad sentence, right? Especially if you add an adverb like easily or quickly. This is known as middle voice, but we’ll save that for another day.
****** This preterite-for-participle switch is pretty common in Tyneside English – my excellent sociolinguist colleague Dr Dan Duncan has written about it, and also looked at the (less common) opposite, where the participle can sometimes be used for the past tense, e.g. in I seen her this morning (rather than I saw her). Notice that the preterite and participle forms are the same for regular verbs (I baked the cake and The cake was baked by me). Thanks also to the lovely Tynesider Beth Beveridge who brought the Tyneside variant to my attention in the first place!
A little over a year ago I hopped on a Transpennine Express train to Manchester, bound for Media City in Salford. After one of the most adrenaline-filled days of my life, I was lucky enough to be named part of the 2023 AHRC-BBC New Generation Thinker cohort.
In the last year I’ve not only picked up some writing tips and skills and enjoyed taking part in the three programmes that all New Gens will make in the first year – I’ve met nine incredibly talented, generous and inspiring people, worked with a whole bunch more, learned how to *teach* writing as well as do it, and pushed through so many barriers of discomfort, embarrassment and imposter syndrome that I’m not sure what my boundaries are any more.
Actually, that’s not true. I know that I won’t be able to listen to the final programme myself. But I *am* proud of it and so I’d love it if you’d listen on BBC Sounds right here, and if you’d rather read, I’ve attached the script below (the script will be slightly longer than the broadcast, but I’m reassured that all the content remains!). IF you do listen or read, please let me know what you think!
I plan to write about the New Gen application and training process in the summer when the next call opens. For now, though, I hope you enjoy a little “linguistics by stealth”, as my wonderful producer Ruth Watts puts it. (And if you read to the end, there are a couple of thoughts that didn’t make it into the studio for you to ponder).
The script
I am named after a wedding cake. My parents’ wedding cake, to be precise, which itself reflected the popularity of the name Rebecca in the late 1980s.
I am renamed thirty years later. On a windy autumnal Saturday, my first child makes a slightly earlier than expected arrival into the world. The midwife places his tiny body into my arms with words she has used and will use over and over again: “Here you are, Mum.”
Mum is a more common name by far than Rebecca, but in the first few months of motherhood, almost no-one calls me by it. In fact, my new name falls only from the lips of medical professionals – people that I certainly did not give birth to.
The person whose presence bestows this part-name, part-title on me does not pronounce it once. He does not yet have the linguistic, cognitive or cultural capacity to call me anything, but within a few short years – months, even – he will have mastered the physical manoeuvres and social knowledge necessary for calling me mother.
This process fascinates me as a parent, but also as a linguist. Not a linguist who learns to communicate in other languages, but one who studies the properties of the human communication system, in all its variety, and how people learn to use it. Though language has been studied for years in fields such as rhetoric, psychology and anthropology, the field of linguistics, which applies the scientific method to the study of language, is much younger. Growing out of philosophy and philology departments through the lectures of scholars like Ferdinand de Saussure, linguistics gained traction as a field in its own right as late as the mid-20th century thanks to innovative and controversial thinkers such as Noam Chomsky and George Lakoff. My research focuses on child language acquisition, an area of interest with roots in psychology that was strongly shaped by 20th century thinkers – on which more later. So, having acquired a child, I couldn’t wait to see how he acquired the language he was surrounded by – in his case, English.
At the very beginning, however, he was busy developing a set of cries to communicate his different needs and desires. The most memorable of these communicated hunger – a plaintive “niiiiiing”, with consonant “n” and the long, drawn-out vowel “i” evoking “need”. The final nasal “ng” required him to press the back of his tongue against the soft palate, completely closing off the mouth from the nose and the back of the throat. This is the same tongue posture that he would need to receive milk safely. That sound “ng”, then, was a figurative and literal demonstration that he was ready for food.
Given his propensity for nasal sounds like “n” and “ng”, I may have got my hopes up that these, and the other nasal consonant in English, “m”, might guide my child’s first words, and that my new moniker, mum, might be early among them. Indeed, as anthropologist George Peter Murdock demonstrated in the 1950s, maternal names across the globe overwhelmingly include nasal consonants, from Turkish anne to Arabic umm, Basque ama to Tagalog nanay. Linguist Roman Jakobson surmised that maternal names, especially the childlike so-called “nursery names”, are rooted in the nose for a very practical reason. When feeding, whether at breast or bottle, air can only pass through the nose, and so feedback from the child during this activity, which can take quite some time, is often expressed through nasal murmurs and mutterings. Jakobson also suggests that early utterances of “mamama” are not in fact utterances intended to refer specifically to the female caregiver, but rather an expression of the child’s general wants and needs of the kind that mothers might often attend to.
This idea emerged in part from diaries kept by one of the most famous fathers in linguistics, the father of child language studies, Werner Leopold. Leopold, working at Northwestern University in the 1930s and 40s, kept a diary of his daughter Hildegard’s earliest speech as she acquired both German, Leopold’s first language, and English, her mother Marguerite’s language and the language of her environment. Leopold was particularly interested in ensuring that Hildegard could indeed acquire German despite the dominance of English around her, and while some diary and observation studies of child language had been conducted by psychologists and educationalists, rare was the study that had analysed in detail the developing sound system and grammatical rules demonstrated in child speech. Leopold, however, was trained in the close transcription of sounds and fine-grained analysis of the structural interactions between parts of speech. He then applied this knowledge systematically to his observations of his daughter, later in life referring to her as his “ants and bees”, by analogy with the creatures studied in the hard sciences.
How did our ant under the microscope, Hildegard Leopold, refer to her parents? Leopold wrote that, for Hildegard, mama “has no intellectual meaning and cannot be considered to be a semantic alternative of papa, which was learned with real meaning at 1 year of age. Mama with the standard meaning,” he says, “was not learned until 1 year 3 months of age.” Another contemporary linguist, father and diarist, Antoine Grégoire, made a similar observation – his son used the sound sequence mama to express a need, particularly hunger, irrespective of his addressee, but used papa as a name to remark on the appearance of either mother or father. In the earliest stages, then, Mama is not mama by name, exactly, rather she is expected to respond to the needs expressed by those same sounds.
So the name on the tip of baby’s tongue is, quite literally, daddy. Place the tip of the tongue behind your teeth, close the rest of your tongue against your upper teeth, let air pressure build, and release it. Depending on whether or not your vocal cords were involved, you have just produced a /t/ or /d/ sound. These sounds, along with /p/ and /b/, predominate in paternal names across language families. Examples this time include Bulgarian tatko and Chichewa adadi, Kurdish bavo and Icelandic pabbi, all using the lips or the tongue, but not the nose, to push daddy’s name into the air.
/m,n,p,b,t,d/. These sounds are all made at the front of the mouth with complete closure of the lips, or the tongue to the teeth. They are preceded by brief silence, or muted murmuring, before their explosive release into a vowel like /a/ – open, noisy, resonant. Nursery names for parents, the mamas and nënës, babas and papás, are characterised by the repetition of vowels and consonants, repeated movements of the mouth from its most extreme open, resonant position to its most complete closure and near silence. This seems to me an allegory for parenting, where peace heralds chaos, which cedes to peace again. These movements between extreme postures are basic features of children’s earliest words, as they continue to practise and move towards mastery of their facial muscles.
Though designed, if unconsciously, to trip off the tongue, the names mummy and daddy are not equal. This became abundantly clear to me when I followed in Leopold and Grégoire’s footsteps, and many others since, in recording our family interactions, with a view to learning more about how a single child acquires language.
The diary of my child’s language journey comprises to date 414 audio recordings, an Excel spreadsheet of his first 500 words, an ever-growing file of notes in my phone, and scraps of paper stuffed in pockets, notebooks and bags. In this latter alone am I truly Leopoldian in my diary-keeping – but I am very grateful for the technology now available to me, that allows me to examine in fine detail the melodies of my child’s speech as he grows, and witness over and over again how he develops into a competent, clever conversationalist.
But though technology may develop rapidly, human change moves at a much slower pace. Leopold and Grégoire noted how daddy is used as a referring term, as a designation for some other person in the world, much earlier than mummy. Other linguists too have shown that children often overgeneralise Daddy as a name to refer to female parents, and even other caregivers and adults, while mummy arrives later, and is reserved for mothers alone.
In all these respects, my child is a textbook specimen. Daddy was his second recognisable word, uttered at 11 months old. /m:/ and /mə/ sounds soon followed…to represent mooing, of course. At 12 months, he started to refer to me using a word from British Sign Language, learned in a baby sign class. This word was produced manually, so he would tap the crown of his head with one hand, often looking in my direction. /m:/ then became his vocalisation for the moon, and after two more full passages of its waxing and waning, my inconstant child finally, at 14 months old, pronounced the word mummy. By this point, daddy and the BSL sign had become labels freely used for any caregiver in the space, and to this day I am still occasionally called on as daddy.
However, my guise as daddy has a specially limited application that illustrates the incredibly sophisticated abilities of small children to manage relationships and conversations, even before they are reliably out of nappies. Parental names, like any given names, can be used as vocatives, that is, to call on people for their attention. Children start out by using names as standalone calls – a cry of Mummy! or Daddy! To find out what happens next in children’s speech, I turned to modern child language diarists. This does not require a visit to a romantic library or archive – recall that child language acquisition is a young field of study. Instead, within a few clicks, I am scrolling through masses of child language recordings on the online database known as CHILDES, the Child Language Data Exchange System, and find that as early as 2 years of age, children start to use parental names in the middle of conversations, particularly at the end of a conversational turn, to invite a response from their conversational partner. In this way, they build and maintain a relationship with the people they’re speaking to, just as adults do. Turning again to my own notes and diaries, I noticed that I was daddyonly when my child wanted to attract my attention anew. There is no confusion here – once he has my attention, I am, utterance-finally, only mummy.
However, in other families, naming conventions are much less clear cut, and a negotiation process may be required to ascertain who, if anyone, bears the name mummy. In queer families, particularly those with two female-identifying parents, there are two equally obvious candidates for this title. And as we’ve already established, the person with the deciding vote, the child, will not cast it for quite some time. So who names who, and how?
The LGBTQ Parental Names Project, run by the website Mombian, surveyed queer families and uncovered a range of sources for parental names, as diverse as the families themselves. For some parents, their heritage provided a route to distinction. A family with one Geordie mother and one mother from the South of England, for example, might very naturally find itself with one mam and one mum. This route may not always bear fruit, however – in an English-Danish household, using Danish mor could confuse a cry for mum with a demand for, well, more!
Other parents really did wait for the child to have their say, and in some cases, the child chose to use the parents’ given names, perhaps in combination with a parental name. Some children clung to that all important nasal murmuring /m/ to mark their mothers as the same, with two different open vowels in mama and mummyto tease them apart, where others, like poet Maggie Nelson’s stepson, played with the placement of /m/ at the lips, with mommy becoming bombi, reflecting both her motherhood and their favourite shared game, Baby Bear.
No matter what the make-up of your family, parental and caregiver names reveal a fascinating process of redefining yourself relative to others: to the new person who has arrived in your life, to your partner, and to society’s expectations…or rather, being redefined, refashioned, redubbed, over and over.
Raising a child is a period of constant change, and I have found that my name has changed as my child has grown. A brief dalliance with my given name was toyed with and quickly dropped. Now that he has left the nursery and its babyish reduplication of consonants behind, I am less often called mummy. Despite this, play with the some of the sounds of mummy cannot be resisted, and every so often I am dubbed pumpy. Linguists here may note how, to move from /m/ to /p/, airflow through the nose stops and the vibrations of the vocal cords still. Native North Easterners, on the other hand, will note the childish humour in naming your parent after a dialect word for flatulence.
My most common appellation right now, however, is mother. Whence this formality? My schoolchild’s unwavering dedication, at least for now, to the short stories of Enid Blyton on audiobook, a world in which mothers’ strict interdictions and punishments provide a springboard for their children’s fantastical fairy-led adventures. Whether my new moniker is an indictment of my parenting techniques, I prefer not to know, but for now, my child, feel free to call me Mother.
Ideas left in drafts gone by…
You may have noticed that my title owes a debt to the fabulous art form of drag, in particular American forms of drag spearheaded by the global phenomenon RuPaul. I wanted to discuss the use of the term “mother” in Black and Latina New York drag houses, and latterly in internet speak, but it didn’t fit smoothly enough, and in any case, the wonderful sociolinguist Dr Christian Ilbury from the University of Edinburgh does it much better than I could in this brilliant article, written by Soaliha Iqbal.
I’d have also loved to discuss how parental names are acquired cross-linguistically, and how in some cultures, they aren’t in children’s earliest lexicons. Why? Lots of different reasons, but some cultures have very different approaches to addressing pre-linguistic babies than the culture I was raised and am raising my children in – some don’t address speech to babies at all, or wait for them to produce specific words before they can be considered to have the linguistic skills to converse with. These cultures tend to have a lot more child-to-child speech than Western cultures now do, which shifts the focus of what children hear, from whom, and with what intentions.
This may seem a very strange question. Surely children can only know about language that which they hear, see or experience from the language users around them? After all, a child only learns the language(s) they are exposed to. No child in the UK, for example, grows up learning Auslan, unless they are exposed to it by an Auslan-signing parent.
But this question is a (less provocative!) rendering of one of the biggest open research questions in child language, and one which has split child language researchers, sometimes acrimoniously, since the mid 20th century.
You may be more familiar with this question framed as the “nature vs. nurture” debate, or the innateness debate. Both of these framings I find very weird. When you drill down, all child language researchers believe that both nature and nurture play roles in the acquisition of language by children. The real debates are around the nature of nature and the nature of the nurture. So let’s dive into exploring the two main approaches to these issues, starting with the group that proposes language-specific innate knowledge.
(Full disclosure first: I was trained and now work in the generativist tradition, I know it better, and I think it is more often misunderstood than the constructivist tradition, so I spend quite a bit more time on what follows describing the generativist point of view. Even so, I hope you find it interesting, and somewhat balanced in terms of critique.)
The Domain-Specific approach (a.k.a. the Generativists)
These are the scholars typically positioned as the “nativists”. They’re responsible for creating All the Acronyms (LAD, UG, PLD MMM*…) and are often accused of not taking the other side seriously, mostly because they don’t engage with their work very often (which is, of course, not good scholarship).
But generativists are very serious about their main claim: that human beings are born with some knowledge about language that they use to make sense of the bewilderingly complex language input they receive. This is known as domain-specificknowledge because, quite simply, it’s knowledge that pertains only to the domain of language, and no other cognitive domain. You may have also heard of it referred to as Universal Grammar – some language knowledge, even rules, that all children can use from birth.
Why make such a claim? Well, in part it is because it’s striking that children learning different languages actually pass through very similar developmental stages – adults do the same too when learning artificial languages, irrespective of their first language. This suggests that we don’t just have general learning biases or preferences, but that some biases exist that apply specifically to linguistic information.
The birth of a language: Nicaraguan Sign Language
One of the most compelling examples of this can be seen in the development of Nicaraguan Sign Language (NSL). NSL grew out of the opening of the first state-run school for deaf people in Nicaragua in the 1970s. Students came from all over the country and did not share a language, using instead a range of “home signs”. But as they interacted in the playground, conventions of use developed among the students – a lexicon with some rules. These rules, however, didn’t really resemble other languages. They did the job, and the children communicated and flourished. But a lot of the signs and structures relied heavily on representing events and things in the world fairly literally, and didn’t make use of many abstract markers in the way that full natural languages typically do (things like tense, aspect, person agreement, etc.).
When new, younger students arrived, they took this fledgling system and (entirely subconsciously) generated a true language grammar for it. The younger students used their innate compulsion to build a linguistic system, using highly arbitrary features like space and handshapes to create a complex system that could express more efficiently complex, abstract idea. This system – NSL – has a grammar that is fully recognisable as a natural language grammar. That’s to say that it is hierarchically structured, it doesn’t “count” (there isn’t a specific type of word that must be the third word in the sentence, for example) and its rules are regular in many of the same ways as any other language.
This brings us to another motivation for the generativist approach to understanding language acquisition: for all the logically possible ways in which languages *could* differ, they tend to structure their constituent parts along very similar lines.
What about the Poverty of…
Note that I haven’t mentioned (directly) a theory often cited as a motivation for a generativist approach: the Poverty of the Stimulus. It’s an idea that grew out of “Plato’s Problem” – the question of how humans extract so much information from limited evidence in their environment. With respect to language specifically, it is used to suggest that children simply don’t get enough linguistic evidence to be able to build a language grammar as quickly and as accurately as they do.
And for sure, it’s amazing that by the age of three, small children can engage in long narratives, ask questions, follow complex instructions and reason about the world, even though they can’t tie their shoelaces and some may still be in nappies. However, linguists who made (and make) this kind of argument are often only interested in syntactic strings, which don’t take into account all the *other* cues and pieces of information that actually accompany those strings when spoken or signed in context – intonation, gesture, context, growing world knowledge. Moreover, if we don’t have theories about children’s ability to reason, remember and recognise patterns across the information they receive, then the Poverty of the Stimulus is pretty vague. How much information is enough, and what information are children actually capable of using?
Speaking of vagueness, I will admit, as a card-carrying generativist, that claims about the content of possible domain-specific knowledge remain bafflingly vague. So let’s examine a couple of the more worked-out versions of Universal Grammar in more detail. Note that I’m skipping over quite a lot of historical detail here to focus in on just two approaches to understanding domain-specific knowledge – if you want to know more, come and do a degree with us in linguistics ;).
Rich UG: Principles and Parameters
In the past, some scholars assumed that Universal Grammar consisted of a very rich store of innate knowledge made up of universal linguistic principles and parameters – possible “settings” for those universals in different languages.
A famous example is the pro-drop parameter. Some languages allow users to “drop” the subject of the sentence (that is, not say it out loud). These languages include Italian, Spanish, American Sign Language, Mandarin Chinese, and many more – around two-thirds of the world’s languages, as far as we know. The exact rules that determine when you can drop a subject might differ, but the fact that you can drop a subject is what links them. Take examples (1-2) from Italian, and compare them with the English translations.
(Io) sono felice. “I am happy.”
Piove. “It rains.”
In (1), the Italian first person pronominal subject “Io” is optional – “Sono felice” is itself a perfectly grammatical sentence in Italian. But in English, “I” is obligatory – “Am happy” would be considered ungrammatical most of the time. In sentences like (2), there is no subject in Italian, because weather verbs like piovere (‘to rain’) just don’t need subjects at all. But in English, we insert the expletive or pleonastic pronoun “it” to get “it rains”, because the grammar’s need for a subject is so strong that it doesn’t matter whether it actually refers to anything or not. It’s a purely grammatical requirement. Other languages that require the subject to be overt, like English, include French, Indonesian and Mupun, to name a few.**
How does this relate to acquisition? According to a theory that assumes principles and parameters, children will be (subconsciously!) listening out for how their language expresses subjects because they’ll ‘know’ it’s an important point of variation for grammar with a roughly binary set of values – either you can drop your subjects, or you can’t.
A theory like this is useful because it helps make predictions about what children might or might not be doing during language acquisition, which you can then test by looking at language corpora (sets of recordings of children) or by running experiments. Taking pro-drop as an example again, it is a common observation that English children drop subjects in their early speech, until around age 3. A theory like principles and parameters provokes an interesting research question – do English-acquiring children drop subjects because that’s grammatical for them to start with, because pro-drop is a default setting (a language-internal explanation), or for some other reason, like reduced processing ability (a language-external explanation)?
So what are English-acquiring children doing? They seem to be just missing out the very edge of their utterance, or in full linguistic parlance, the top-most part of the structure (given that sentences actually have hierarchical, not linear structures. More on that another time). Why might they do this? Linguist Luigi Rizzi made an influential proposal in the early 1990s, refined in the 2020s with colleagues Naama Friedmann and Adriana Belletti, that children learn sentence structure from the ‘bottom up’, with layers of information emerging in sequence, which may be “truncated” if their processing capacities become overwhelmed. According to Friedmann, Rizzi and Belletti’s “growing trees” hypothesis, children learn the structure of a sentence’s verb phrase (with any objects) first, then grow into marking tense and aspect, then into marking the subject, followed by things that mark how the sentence fits into a discourse, for example the wh-word in a question.*** The claim goes that at the point at which English-acquiring children are dropping subjects, they know that they are needed in English, but they’re still working out exactly what they look like and how they relate to the rest of the structure. All this work sometimes leads to truncation of the sentence – or in tree-surgeon parlance, the subject gets lopped off.
Though Principles and Parameters provided interesting ways to approach language acquisition (and language description more generally), it’s long been clear that it’s not a psychologically valid proposal for the domain-specific knowledge children might be born with – it is quite improbable that children’s innate tools for making sense of language would take such a highly specified form.
Parsimonious UG: Merge and Agree
A newer approach to domain-specific knowledge, deriving from an article by Noam Chomsky in 2005, proposes two processes (rather than a number of principles) that drive how children unpick their language input. Those processes are Merge and Agree.
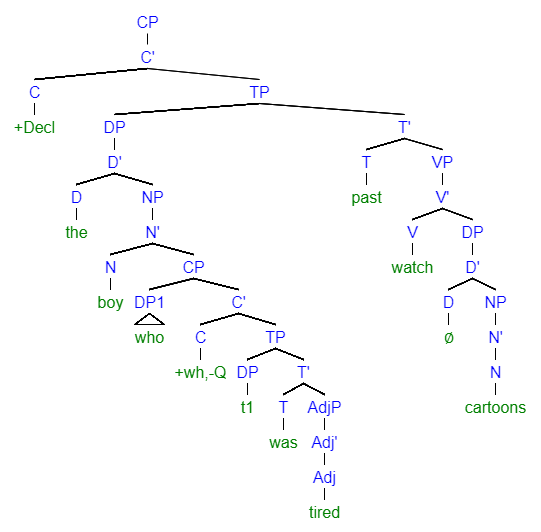
Merge is, briefly, the process of taking two things (words, phrases, clauses…) and combining them to create a new linguistic object. Merge builds hierarchical structures, and we already have plenty of evidence that language is hierarchical, not linear. Grammatical rules reflect this, processing reflects this, and acquisition respects hierarchical structure.
An ‘syntax tree’ capturing hierarchical relationships in the statement “The boy who was tired watched cartoons.” For cool work on how even young children know that the relative clause is contained within the subject, take a read of Crain and Nakayama (1987)
Combining objects means that some relationship is formed between those objects – that they come to share or express some feature that we can use as language users to make meaning. So the language user needs to be able to recognise what features drive the combination of specific objects, as this will help them parse structure accurately (understand) and build new structures (produce language). The process of forming relationships between language objects is called Agree. To apply Agree, the language user also needs to form a set of features that are relevant in their language that can be recognised in the language objects, and which they could use again and again to parse any of the infinitely many sentences they might be exposed to in their input.
Let’s (try to!) get a bit less abstract now and return to the issue of pro-drop, with help from linguist Theresa Biberauer, who looked at pro-drop from the point of view of Merge and Agree in 2018. She argued that children acquiring their first language will be constantly looking for patterns across their language and looking for features – some abstract, some maybe less so – that link the structures in their input. As English-acquiring children very rarely hear sentences without subjects, and receive evidence for subjects that carry no independent meaning (expletive “it”), she argues that they won’t look for features that explain subject patterns because, quite simply, there’s no need to. There’s no ‘pattern’ to explain in that sense – you just need to have a subject, and English-acquiring children will pick this up early on, leaving their subject-dropping in production to be explained by other factors such as processing, or still needing to build the parts of the grammar that will connect up the subject with the main verb, such as auxiliary verbs.
The input to Italian- and Mandarin-acquiring children, however, leads them to pose a question – under what circumstances should I drop subjects? They then need to work out what features correlate with dropped subjects. For Mandarin, children will work out that what really matters are discourse features – subjects (and objects) can be dropped when they are topics that are somehow familiar in the conversation already. For Italian, children must realise that discourse matters – familiar subjects can be dropped – but grammatical agreement matters too. Subjects can be dropped because the verb is marked according to the person and number of the subject in Italian – in example (1) above, the verb form sono is the first person singular form of essere (‘to be’). But verbs aren’t marked for the person and number of the object, so objects can’t be dropped.
Noticing these features isn’t just useful for pro-drop, however! Being able to recognise topichood, subjecthood, person and number is also useful in both Mandarin and Italian for other aspects of grammar, like word order, and also for learning how intonation works. So having an innate compulsion to look for relationships between language objects really will speed acquisition along, because the features that characterise those relationships will pop up again and again in the broader language system.
Just because it ain’t language specific, doesn’t mean it ain’t innate…
You’ll note that, in the case of “parsimonious” UG particularly, there are implicit references to cognitive processes that aren’t domain-specific, like pattern-spotting, pattern-matching, awareness of frequency, and more. This is because generativists also make room in their theories for domain-general learning mechanisms – in other words, cognitive processes that aren’t specialised for language but that are used to learn language. We’ll talk more about these below, as they are the key tools in the theoretical arsenal of “the other side”, but they are crucial for the application of Merge and Agree, and are included in generativist theories as “third factors” – factors that aren’t domain-specific knowledge or the input itself.
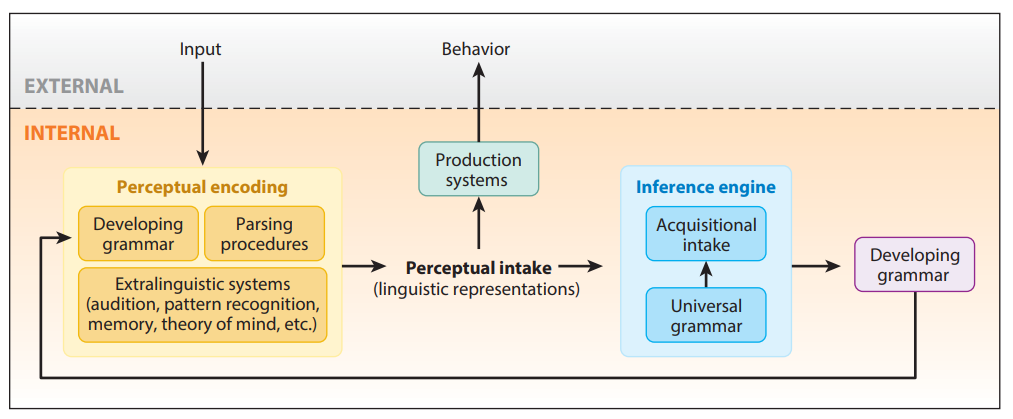
This label gives you a bit of a clue – these ‘factors’ aren’t the things that generativists are, generally, most interested in. But lack of interest doesn’t mean they’re ignored altogether. Indeed, some generativists take the interaction between general cognitive and language-specific processes very seriously. Linguists like Jeff Lidz and Annie Gagliardi build domain-general processes into their models of language acquisition in just the way described above – noting that general cognitive processes must apply to language input before language-specific processes, to provide filtered input that children could plausibly assess for where Merge applies, and what Agree processes are at work. They map their model in the diagram below, taken from their 2015 paper:
Figure 1 from Lidz and Gagliardi (2015). The processes in the yellow block are basically domain-general processes. ‘Universal Grammar’ would, according to Chomsky, Biberauer etc. refer to Merge, Agree and a template for linguistic features.
Theresa Biberauer also takes seriously the idea of “maximising minimal means”, that is, using and reusing features and observations you’ve already made. This is a domain-general process that would be useful for making sense of lots of different types of input. But with respect to language acquisition, she argues that it is a crucial third-factor used by children as they apply Merge and Agree to their input, and that it also drives some of the restrictions on variation that we see in natural language.
You’ve mentioned input a lot. I thought generativists weren’t too bothered about it…?
I think the most misunderstood aspect of the generativist approach to language acquisition is generativists’ stance on input. It is true that some generativists will take the “target” for acquisition to be the grammatical rules of the relevant language at a general, population level (i.e. what is generally considered to be grammatical in that language). Generativists are also often interested in comparing acquisition trajectories across languages so, again, they generalise across individuals and consider acquisition at a population level. This is in contrast to constructivists, who typically take into account only the kind of language that the individual child experiences – that is, the language used by their families and caregivers.
It’s pretty obvious how the two ‘targets’ here might differ, and how that would affect predictions that you would make. But input is always important, and generativists don’t assume or predict otherwise.
Given that we’re thinking about input, let’s turn now to our other set of players, for whom input drives not only acquisition, but much of their theorising and reasoning.
The Domain-General crew (a.k.a, amongst other things, usage-based researchers or Constructivists)
It’s a little harder to define a “main” claim of researchers for whom domain-general knowledge is the child’s only tool for making sense of their language input. That’s because there are a lot of different types of domain-general process to investigate – working memory, long-term memory, statistical generalisation, sensitivity to frequency, and so on. But something that is key for constructivists like Ben Ambridge and Elena Lieven, which differentiates them from generativists, is that children go from specific observations about their individual language input – e.g. storing particular phrases that they have heard/seen – to gradually generalising abstract rules. Memory, therefore, plays a major role in a constructivist account, whereas even the “third-factor”-interested generativists rarely, if ever, mention it.
What children can plausibly add to memory, of course, depends on what *exactly* they are exposed to. Sensitivity to frequency is a core theme in constructivist theories – children will appear more adult-like when they can use a stored phrase or string from memory, and less adult-like when the task they’re performing can’t be addressed using stored material. That frequency is important in language development is well established – it plays a role in language change in many levels of language, as well as language use, language processing, and patterns that emerge across languages (recall, this was an argument for domain-specific knowledge too…)
Given their focus on individualised input, constructivists also insist on the importance of understanding language acquisition as happening in interaction. As such, studies of the acquisition of pragmatics are dominated by constructivists, with Catherine Snow and Thea Cameron-Faulkner leading the charge****.
Right. So…null subjects from a usage-based POV?
Sorry lads. That’s what I wanted to write about here, but I cannot find an account of English-acquiring children’s null subjects from the constructivist side of things. I did find an account for Spanish, a pro-drop language like Italian. Hannah Forsythe and colleagues argued that the frequency in input of different types of pronoun affects when they begin to be dropped in adult-like ways – first and second person subjects are more frequent than third person subjects, and children achieve adult-like rates of dropped and overt subjects in first/second person cases first, before abstracting the same rules to third person subjects.
As for English null subjects, my guess, but this is only a guess, is that there are three routes to take to explain them using a constructivist lens.
One is to put all the blame on processing limitations of various types – which is of course, ultimately where we landed in the generativist approach too. Reading around a bit, and talking to colleagues of a constructivist persuasion, this seems like a bit of a cop out.
My excellent colleague Dr Nick Riches suggested a second take: subjects don’t add much grammatical information to an utterance – especially when first and second person subjects are so much more common in child speech than third person ones. This is in contrast with objects, which are important for indicating the argument structure of verbs (and, of course, the less obvious identity of the object). So if children are going to drop any information (because of gradual acquisition, or processing pressures), the subject is the least informationally dense element.
The third route is to assume (as constructivists do) that the child’s grammar is very different from an adults, and then go looking at the rate of utterances that have no subjects in the input *regardless* of the morphological form of the verb. Key here are imperative verbs – these are very frequent in child input and *don’t* require a subject but, in English, are not overtly marked as imperative. They look superficially exactly the same as most verbs in the present tense, and infinitives too. I guess a constructivist could argue that imperative verbs could provide sufficient evidence for certain verbs not needing a subject, at least in very early child language. To argue this you’d have to have a story about how children ignore the specific pragmatic use of imperatives, but maybe that’s doable.
It’s also important to note that usage-based approaches tend to focus, perfectly legitimately, on children’s production in terms of evidence for their grammar. This is of interest to generativists, of course, but generativists are also interested in children’s comprehension. So while both approaches will look at production in their accounts, generativists are also likely to probe children’s grammar by looking experimentally at how they react to grammatical and ungrammatical sentences.*****
What all this illustrates, though, is how the “two sides” here are not two sides of the same coin. At best, we’re looking at the head of a pound coin and the tails of a 50p. The two approaches work within the same field, but often look to answer quite different questions – and they’ll make use of different data to support their own arguments. As it turns out, those data don’t necessarily overlap all that much, *even* in a language as heavily studied as English.
I’m doing my A-levels. How can I make sense of all of this for the exam?
I have a few ideas here, but this is a topic I’m probably going to return to in more depth in a future blog post too. Also, bear in mind that I’m pretty well acquainted with the specifications for some of the large exam boards (particularly AQA and OCR), but I’m still not as steeped in them as trained teachers are! But if you’re interested to know my initial thoughts, then please continue…
Key to the exam first and foremost (and to linguistics in general) is the ability to accurately *describe* children’s production, so above all else, ensure that you are confident in labelling parts of speech and morphemes and that you can spot and describe features like person and number, both for the adult target and the child’s production. Also, don’t focus just on children’s non-adult-like production – give them ‘credit’ for what they *can* do in an adult-like way too, whether that’s producing subjects, using relevant auxiliary verbs, and so on.
Given the direct link that constructivists make between the child’s individualised input and their production, it’s a little easier to see how you could zoom out from transcripts of child language to talk about constructivist approaches to language acquisition. Even then, the role of frequency is hard to address from fragments of transcripts, so to be true to constructivist techniques, you’d have to talk about what you would look for if you had more examples of dialogue from the same child-caregiver pair.
With respect to linking from transcripts to generativist claims, the “growing trees” hypothesis is interesting to link to in terms of evaluating why verb phrase syntax is adult-like earlier than tense and subjects. You can also think about what grammatical features a child needs to work out for different linguistic items that are in the transcript and what interim features they might propose – features are a good way of thinking about and comparing linguistic complexity. As an example, determiners like “the” and “a” differ in terms of definiteness, but “a” is even more complex because it can be used both with specific and non-specific nouns, and is also specified for number (singular only). So there are three features that a child has to learn when trying to pick a determiner, and the determiner options differ in their featural complexity. Imagine what effect that could have on the acquisition of determiners in English.
Notes
*Language Acquisition Device (see ******), Universal Grammar (described in text), Primary Linguistic Data (=input!), Maximising Minimal Means (described in text)…and many more!
**If you’d like to know more about how languages express subjects, take a look at the World Atlas of Language Structures. You can also find lots more information about the structures of hundreds of languages all over the world on this fantastic website.
***There’s a competing hypothesis under development by Martina Wiltschko and my very good colleague Johannes Heim, called the “Inward Growing Spine Hypothesis“, which suggests that structure grows inward from the bottom (the verb phrase) and the very top (discourse-related phrases that call on the addressee to respond, like vocatives). I’m not sure either approach is *quite* right, but Wiltschko and Heim’s idea that some of the very topmost structure does come in early is clear from early child utterances. The question is – which parts of the topmost structure? I’m working on my own contribution to this question – watch this space 😉
****Generativists, it should be noted, have spilled a lot of digital ink on one particular aspect of pragmatic acquisition, namely the topic of scalar implicatures. But that’s a topic for another day.
*****Obviously, you can’t just ask a small child whether they find an utterance grammatical or not – in fact you can’t do this until they’re about 6 or 7 years old (and even then, we’d use more child-friendly wording!). But you can interpret children’s behaviour in response to stimuli in lots of clever ways to probe what they do and don’t know about the adult grammar.
******LAD – Language Acquisition Device. A term from Noam Chomsky’s early work to represent an (unspecified) process or set of processes and knowledge that the child is born with and that specifically concern and work over language input. Not in use by generative linguists today.
And a postscript…
I may have become a bit delirious when initially planning this post (I was at a soft play centre too early on a Sunday morning. It does strange things to you) and I ended up casting the two competing approaches as the Capulets and Montagues in a terrible rewriting of the prologue from Romeo and Juliet. Trigger warning: what follows might constitute cultural vandalism…
Two (main) factions, both alike in indignancy In Academia, where we set our scene From old grudges break to new strawmen Where wilful snubs make wilful claims quite mean. From forth the messy output of these groups This messy cross-referenced blog takes shape; Whose well-intentioned overview does aim To make clear where their paths each other trace. Generativists from LAD****** through UG Move, while constructivist claims also persist. I cannot claim to end the feud – not me! – Just reveal of what the arguments consist. The which, if you with patient thumbs scroll through What here I’ve missed, I toil now to construe.
Strange things are happening in the world of education. To the benefit of absolutely no-one, STEM subjects are frequently held up as the only ones worth studying, while technological advances (and misadventures) demonstrate the need, time and time again, for a nuanced understanding of human beings, how they think, and how they move through the world. In short, we all need more of the arts and humanities.
As a discipline that straddles both STEM and arts and humanities, we have a unique opportunity in linguistics to disrupt the current binary discourse (STEM or bust) and muddy the waters wherever possible. Linguists frequently apply the scientific method to that most human of behaviours, language, but just recently, my fabulous colleague Dr Emma Nguyen and I had the chance to squeeze some awareness of being human into a science space.
The scene: STEAM week at a very lovely local primary school. The brief: chatting to year 3 (ages 8-9) about muscles. The topic? Well, as linguists, we were duty bound to present the group of muscles that gave our field its name* – the tongue. The tongue is crucial for spoken language, but what did our 8 year olds already know about how it shapes language sounds?
By year 3, children in English schools have had a few years of instruction in phonics – a system that teaches the most common associations between sounds (phones) and letters (graphs) to help children ‘decode’ written words. The principle is that by sounding out a word’s constituent graphs and blending the corresponding phones, children can break into written English without needing to rely (too heavily) on memorising full word forms.
However, the phonics schemes we’ve come across as parents or in conversation with schools spend very little time on explicitly describing how, where and with what body parts sounds are made. Some schemes even include mascots that make speech sounds despite having no lips or teeth. Teachers say that the sounds made at the very front of the mouth like /p,b,m/ might elicit some discussion about the lips, and sounds like /f,v/ are talked about in terms of lips and teeth. But sounds at the back of the mouth like /k,g,ŋ/? No-one is sure how to talk about how these sounds come into being.
So the tongue and the back of the mouth are as foreign to our year 3s as the Moon. But unlike the Moon, we don’t need a rocket to find out more about them. Instead, we used a little trick sometimes employed in first year university phonetics classes (that would also buy us a bit of notoriety – more on that later).
That’s how the tongue makes sounds? Sweet!
We ran a little experiment, turning Willy Wonka by handing out lollipops** (or lollipop sticks to anyone who didn’t fancy a sweet). We instructed the children to put the lollipop toward the back of their tongue, then we all read together words with different vowel sounds in them.
Lolly stick demo from me… Photo credit: Hotspur Primary School
Emma directs the sweet chorus Photo credit: Hotspur Primary School
This helped demonstrate how open front vowels like /a/, where the lolly (and tongue!) move down and forward in the mouth, differ from closed back vowels like /i/, where the highest point of the tongue is right close to the back part of the hard palate (resulting in a few lollipops stuck to the roofs of mouths).
Sweets in, tongues out Photo credit: Hotspur Primary School
Surprising level of patience and resisting of temptation… Photo credit: Hotspur Primary School
The kids were amazed at how mobile their tongues were, while we were amazed at how disciplined they were at not chomping the lollipops at the first opportunity. NB: the sweets were not a gratuitous choice! They stick beautifully to your tongue to allow you to focus on how your tongue moves without actually inhibiting it from doing so normally. Until it gets stuck to your palate after a close sound, of course, which will happen if you’re (a) eight years old or (b) narrow-of-mouth, like me.
The experiment demonstrated how place of articulation, or the point at which the tongue, teeth, or lips close or come close together, is a really useful way of distinguishing between sounds, and helps us differentiate words like tap and cap. Tap’s initial /t/ sound is made by the tip of the tongue closing up against the alveolar ridge, just behind the teeth. In contrast, cap’s initial /k/ is made by pushing the back of the tongue right up against the velum, or soft palate. It is the position of the tongue alone*** that prevents misunderstandings about wearing bathroom furniture as a hat.
We also showed the kids some MRI videos from the fabulous website Seeing Speech. These give a fantastic insight into the flexibility and precision of the tongue from a side-on view (pretty hard to achieve any other way), with the added gross-out value of demonstrating just how enormous your tongue actually is.
What other muscles affect how sounds are made?
Some children noticed, though, that place of articulation is not the only thing that differentiates sounds. This led to discussion of another set of muscles and tissues that help us produce speech – the vocal folds. We placed our hands on our throats and made the sounds /s/ and /z/ on repeat. The buzzy feeling of /z/ is due to vibrations in the vocal folds as air is forced between them, and this is called voicing.
Experiencing voicing first hand Photo credit: Hotspur Primary School
To get a sense of what voicing really looks like, we played another video, this time of vocal folds in action from above, and then we got creative. Using a paper cup and elastic bands, we created our own voice boxes, using straws to blow across the elastic-band-vocal folds to cause them to vibrate, and even stretching them with our fingers to create higher pitched sounds. This activity was inspired by one described on howtosmile.org.
Building larynxes! Photo credit: Hotspur Primary School
One of the year 3 form teachers is also the school’s music teacher, so we compared out paper cup larynxes to his guitar collection, and I also brought a kazoo along to demonstrate how voicing changes airwaves. But it was the *other* form who gave us an amazing demo of one of their favourite assembly songs to demonstrate pitch changes – a really glorious moment.
Kazoos are a great way of demonstrating how voicing affects the sound waves that we can produce Photo credit: Hotspur Primary School
Did it all work well?
We thought so! The children took part with enthusiasm, asking great questions about how the vocal cords seemed to change shape and about how speech sounds differ across languages. We taught the sessions on two different days, so we knew we’d had an impact on the first group, as the second already knew some of what we were going to talk about (plus they were well primed for the sweets). We will happily take playground chat as evidence of successful learning!
As for the teachers, they thought that increasing awareness of tongue movements could really help some of the children with language delay. Of course, speech and language therapists employ plenty of exercises that do just this, but we reckon there’s a benefit to be had by sharing all this information with children earlier and more generally, embedding it into phonics learning.
Want to know a bit more?
As you might imagine, we couldn’t do much more than that in a 45-minute session, and we didn’t even get onto mannerof articulation****, a third factor in classifying sounds. We didn’t really demonstrate the International Phonetic Alphabet as a method for representing speech sounds, and we’d have loved to hand round kazoos to all (the teachers may have been less pleased with this). If you’re interested in thinking a bit more about place, manner and voicing and how we use these to describe sounds, here are some resources that might be useful (and spoiler: we’re in the process of trying to develop some that will complement traditional phonics programmes too!).
seeingspeech.ac.uk – the IPA chart is organised by place, manner and voice, so have a play with the videos and audio recordings
*From lingua, Latin for ‘tongue’, came the 16th century coinage ‘linguist’, meaning “master of languages” or “one who uses their tongue freely”. ‘Linguistic’, meaning “pertaining to language(s)” was an early 19th century innovation from German linguistisch, fabulously described by the OED as “hardly justifiable etymologically [… but] has arisen because lingual suggests irrelevant associations.” The term ‘linguistics’ for the field of study followed in the mid 19th century, but only really took off (and overtook its main competitor, ‘philology’) in the late 1940s. All info in this note, apart from the Google Ngram, is taken from the wonderful resource etymonline.com: linguist, linguistic, linguistics.
**Maoam Joystixx were far and away the best sweet for this experiment, with Swizzles Matlow Drumsticks as a decent runner-up as a vegetarian/halal option. No, this isn’t an #Ad. Yes, there was an extensive testing period one afternoon ;).
***Yes, OK, context helps too. But sometimes that is absent, and sometimes terrible analogies happen too.
****This is to do with how the articulators (lips, tongue, teeth, etc.) relate to each other, mostly in terms of how close they are. For example, the initial sounds in both tap and sap are unvoiced and made by placing the tip of the tongue at the alveolar ridge, but where there is complete closure of the tongue against the alveolar ridge for /t/, it’s just close to the ridge for /s/, allowing air to hiss through that small gap.