I’d like to share an experiment in developing a language-agnostic build system that does not require the user to specify dependencies between individual build tasks. By “language-agnostic” I mean the user does not need to learn a new language or a special file format for describing build tasks — existing scripts or executable files can be used as build tasks directly without modification.
I call this build system Stroll because its build algorithm reminds me of strolling through a park where you’ve never been before, trying to figure out an optimal path to your target destination, and likely going in circles occasionally until you’ve built up a complete mental map of the park.
Main idea
Most build systems require the user to specify both build tasks as well as dependencies between the tasks: knowing the dependencies allows the build system to determine which tasks need to be executed when you modify some of the source files. From personal experience, describing dependencies accurately is difficult and is often a source of frustration.
Build tasks and their dependencies are typically described using domain-specific task description languages: Make uses makefiles, Bazel uses a Python-inspired Starlark, Shake uses Haskell, etc. While learning a new task description language is not a big deal, translating an existing build system to a new language may take years (or maybe I’m just slow).
Stroll is different. You use your favourite language(s) to describe build tasks, put them in a directory, and ask Stroll to execute them. Stroll does not look inside the tasks; it treats the tasks as black boxes and finds the dependencies between them by tracking their file accesses. This process is not optimal in the sense that a task may fail because its dependency is not ready and, therefore, will need to be built again later, but in the end, Stroll will learn the complete and accurate dependency graph and will store it to speed up future builds.
There is a build system called Fabricate that also tracks file accesses to automatically compute accurate task dependencies, but it requires the user to describe build tasks in a lightweight Python DSL and preschedule them by calling the tasks in the right order, essentially asking the user to do the strolling part themselves. Fabricate is cool and inspired Stroll but I’d like to explore this corner of the build systems space a bit further.
Demo
Stroll is just an experiment and I’m not sure if the main idea behind it is feasible, but it can already be used to automate some simple collections of build tasks. Let me give you a demo. I’m using Windows below but the demo works on Linux too.
Consider a simple “Hello, World!” program stored in the file src/main.c:
#include <stdio.h> int main() { printf("Hello, World!\n"); return 0; }
We can build an executable bin/main.exe from it by using the following simple build script build/main.bat:
mkdir bin gcc src/main.c -o bin/main.exe
Let’s ask Stroll to build our little project:
$ stroll build Executing build/main.bat... Done $ bin/main.exe Hello, World!
When executing build tasks, Stroll tracks their file accesses and stores the discovered information next to the build scripts, by appending the extension .stroll to their names:
$ cat build/main.bat.stroll exit-code: ExitSuccess operations: bin/main.exe: write: efc851e573be26cf8fe726caf70facf924ccdbae5c4fce241fdbe728b3abde76 src/main.c: read: bc31bb10c238be7ee34fd86edec0dc99d145f56067b13b82c351608efd38763c build/main.bat: read: da9a4390693741b8d52388f18b1c5ccc418531bc3b0a64900890c381a31e7839
As you can see, Stroll recorded the exit code of the script, two file reads and one file write, along with the corresponding hashes of file contents.
We can ask Stroll to visualise the discovered dependency graph:
$ stroll -g build | dot -Tpng -Gdpi=600 -o graph.png
The flag -g tells Stroll to print out the discovered dependency graph in the DOT format that we subsequently convert to the following PNG file:
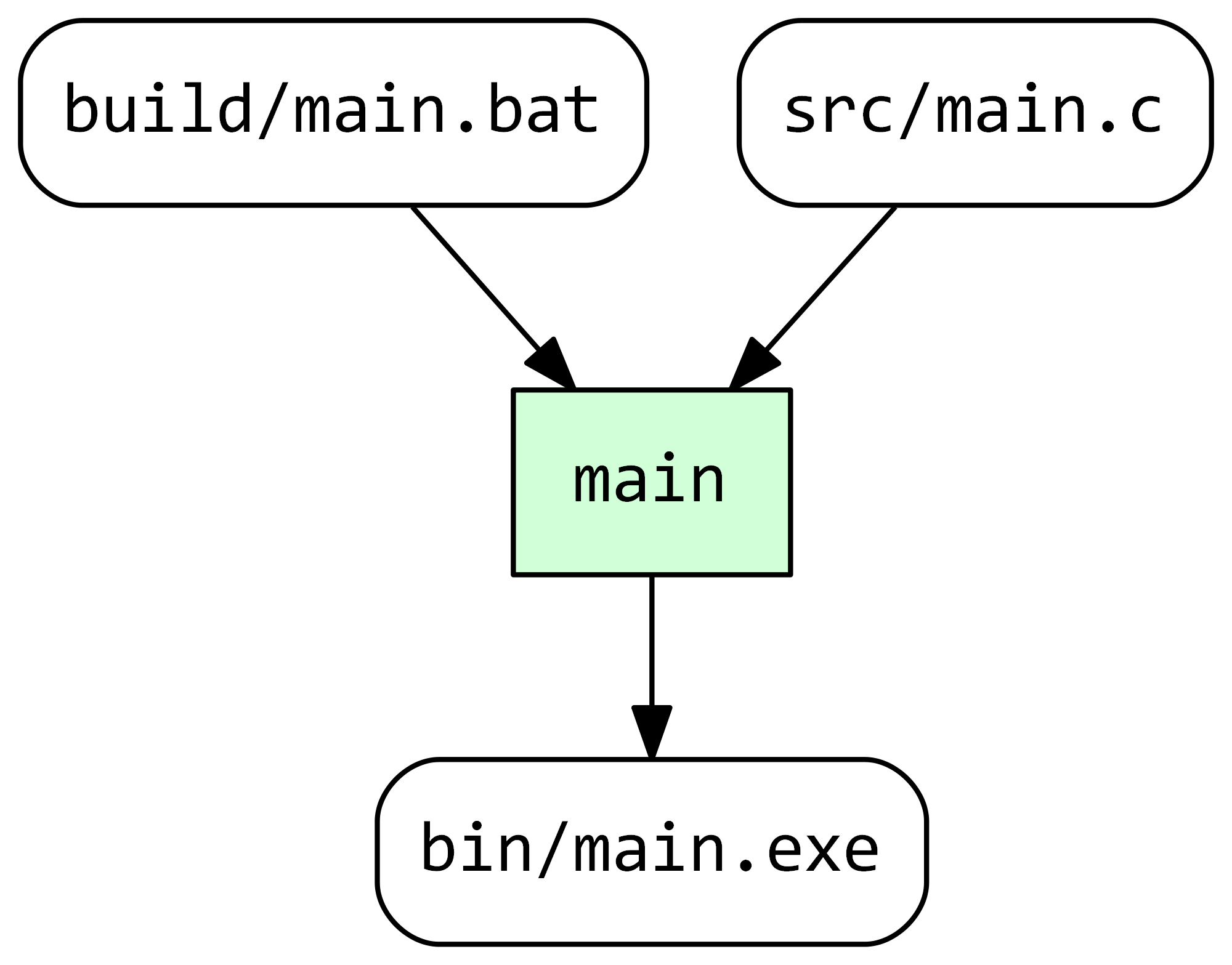
The green box indicates that the only build task main is up-to-date. This means Stroll will not execute it in the next run unless any of its inputs or outputs change. If we modify src/main.c and regenerate the dependency graph, we can see that the task main is now out-of-date:
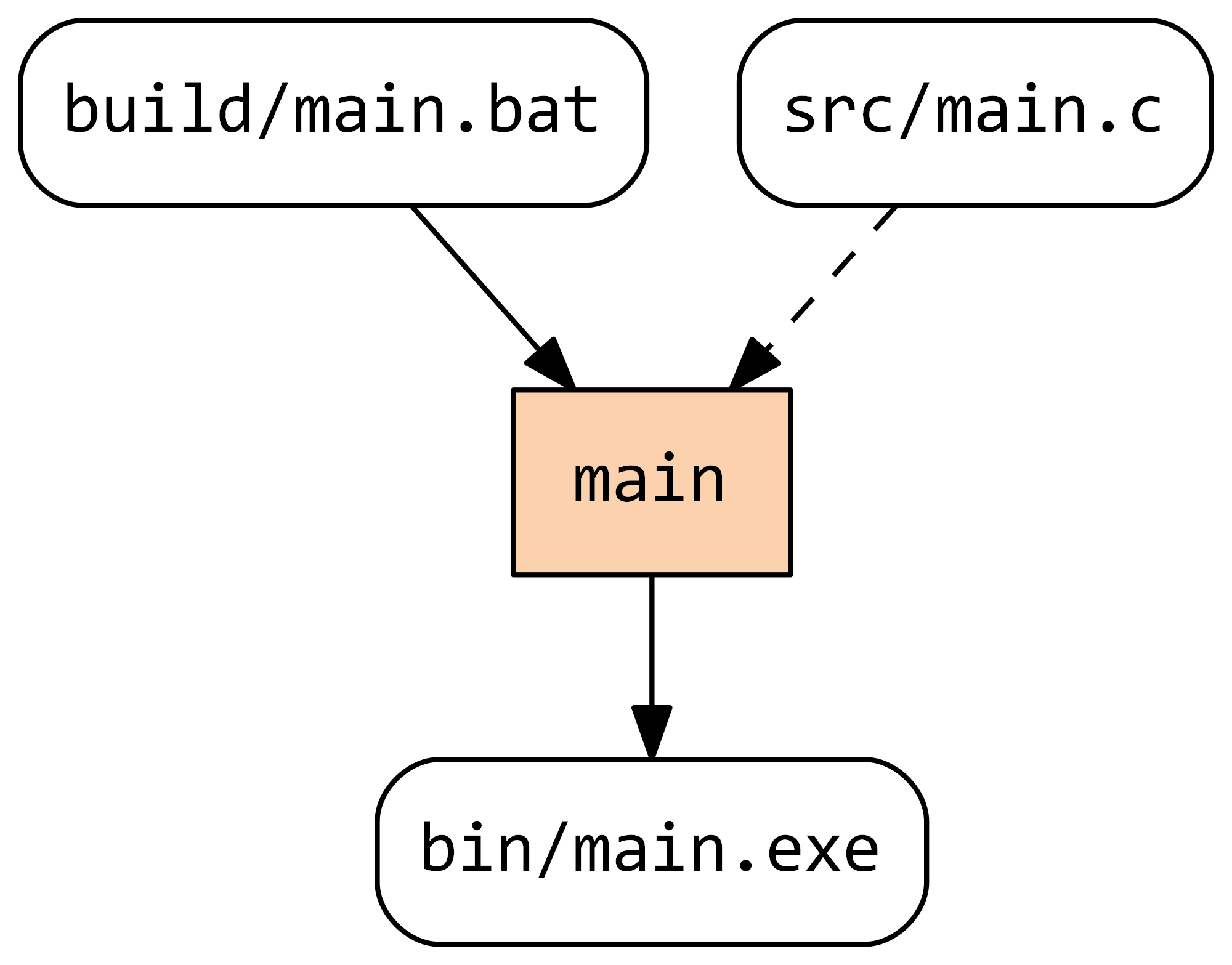
The specific dependency that is out-of-date is shown by a dashed edge. Note that Stroll is a self-tracking build system, i.e. it tracks changes not only in sources and build artefacts but in build tasks too.
To make the example a bit more interesting, let’s add a library providing a greeting function greet in files src/lib/lib.h and src/lib/lib.c:
$ cat src/lib/lib.h void greet(char *name); $ cat src/lib/lib.c #include <stdio.h> #include <lib.h> void greet(char *name) { printf("Hello, %s!\n", name); }
To compile the library we will add a new build task build/lib.bat:
mkdir bin/lib gcc -Isrc/lib -c src/lib/lib.c -o bin/lib/lib.o
If we look at the dependency graph before running Stroll we’ll see:
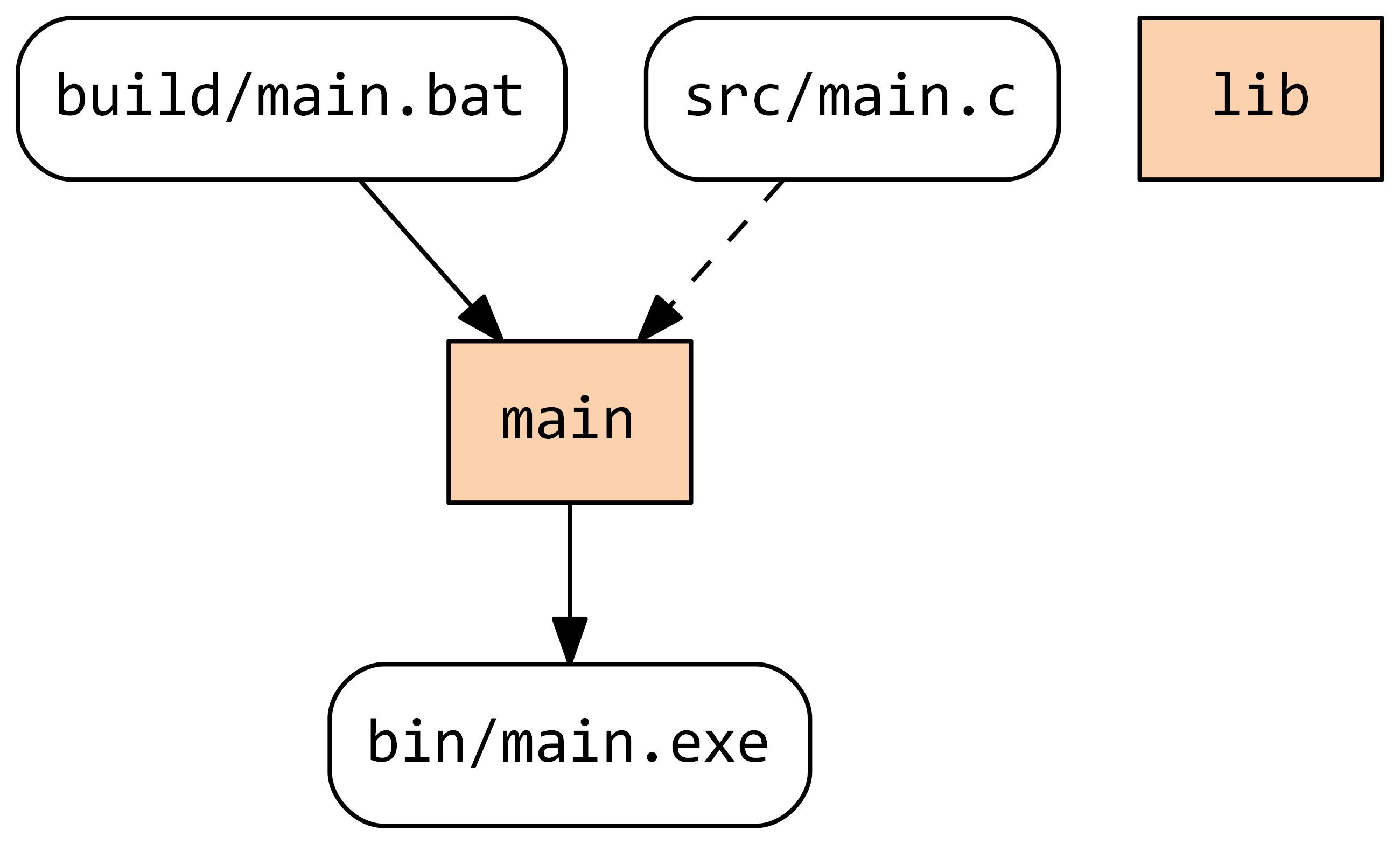
The new task lib appeared in the graph but without any dependencies; it is marked as out-of-date because Stroll has never executed it. If we run Stroll now, it will execute both tasks reaching the following state:
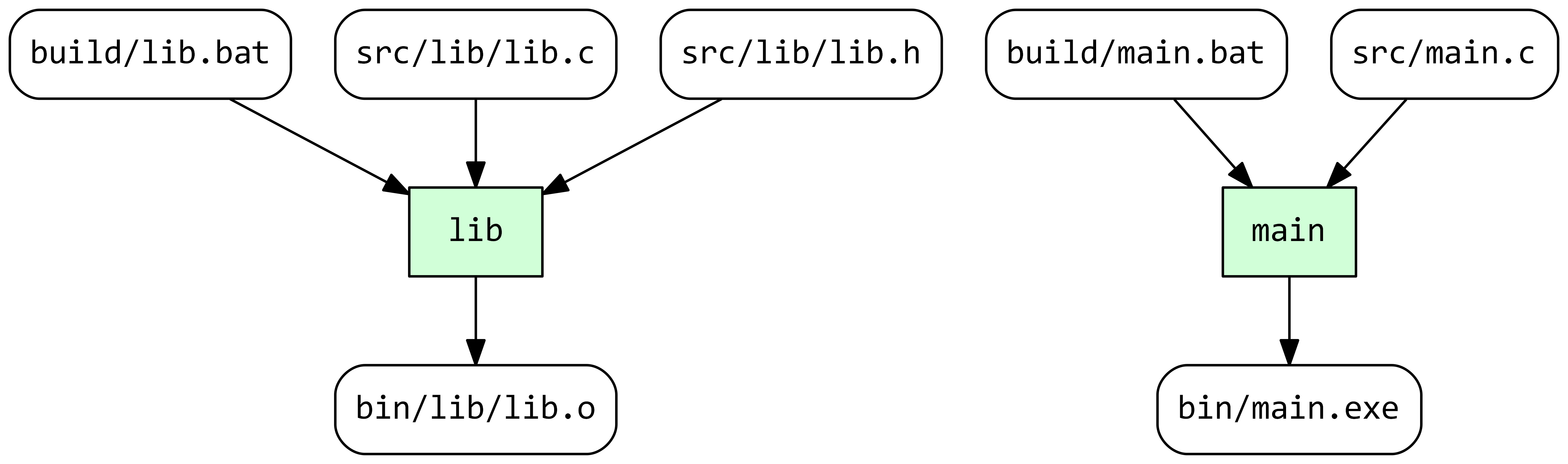
The tasks are currently independent and can be built in parallel but let’s make use of the library by modifying the main source file as follows:
#include <lib.h> int main() { greet("World"); return 0; }
If we run Stroll now, the build will fail:
$ stroll build Executing build/main.bat... Script build/main.bat has failed. Done $ cat build/main.bat.stderr A subdirectory or file bin already exists. src\main.c:2:17: fatal error: lib.h: No such file or directory compilation terminated.
By examining the file build/main.bat.stderr helpfully created by Stroll, we can see that the build failed because we forgot to modify the build script and point gcc to our library. An error is visualised by a task with a double border:
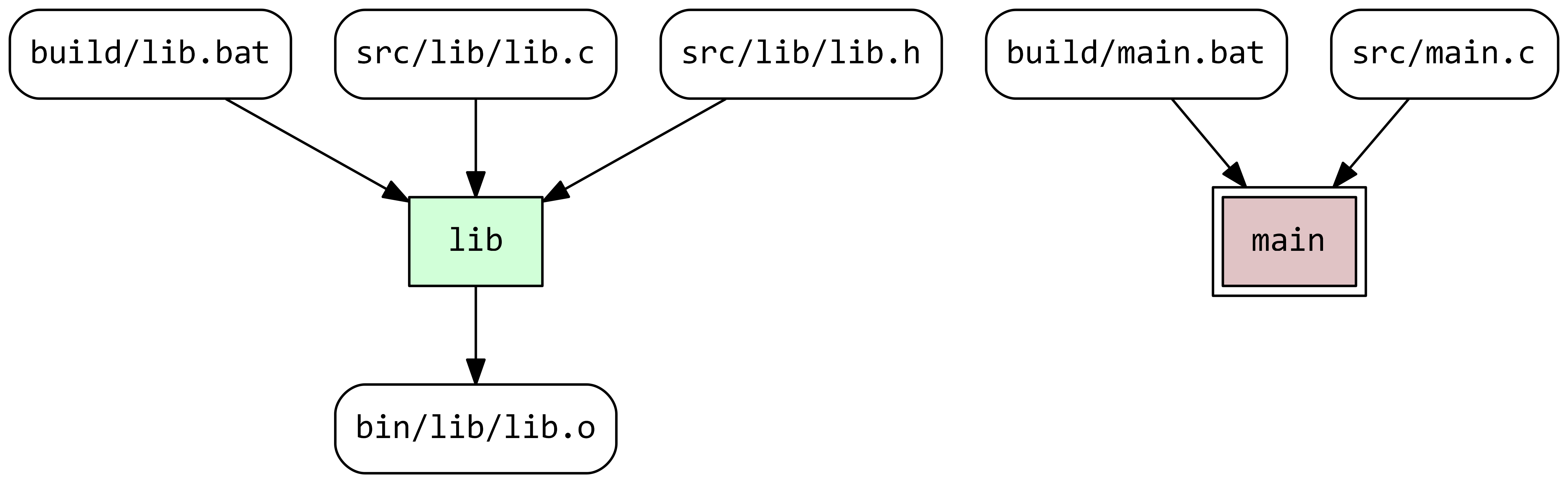
Let’s fix the script main/build.bat:
mkdir bin gcc -Isrc/lib src/main.c bin/lib/lib.o -o bin/main.exe
With this fix, Stroll completes successfully and produces the following dependency graph:
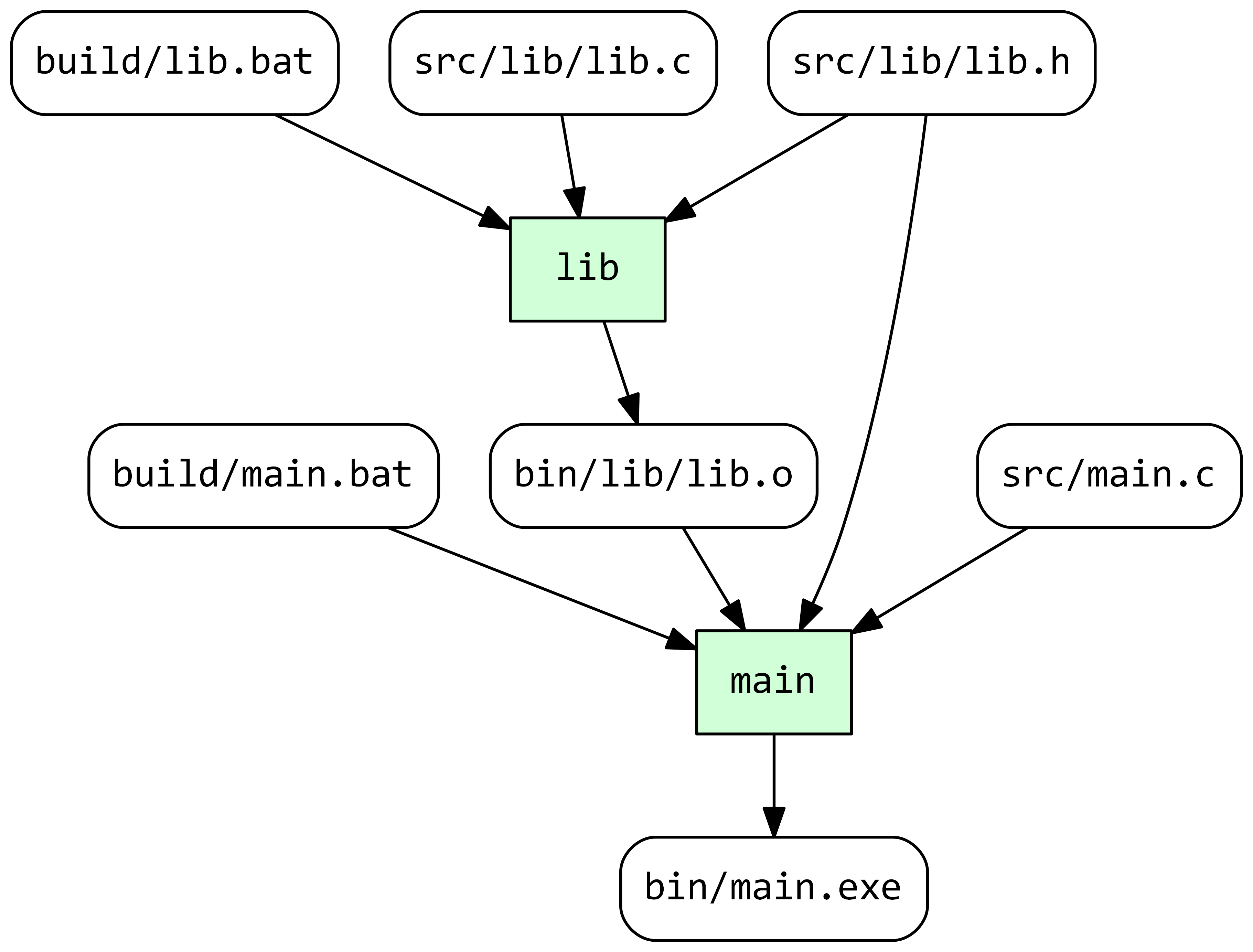
We can now demonstrate the early cut-off feature by adding a comment to the file src/lib/lib.c. Before running Stroll let’s check that this change makes both lib and main out-of-date:
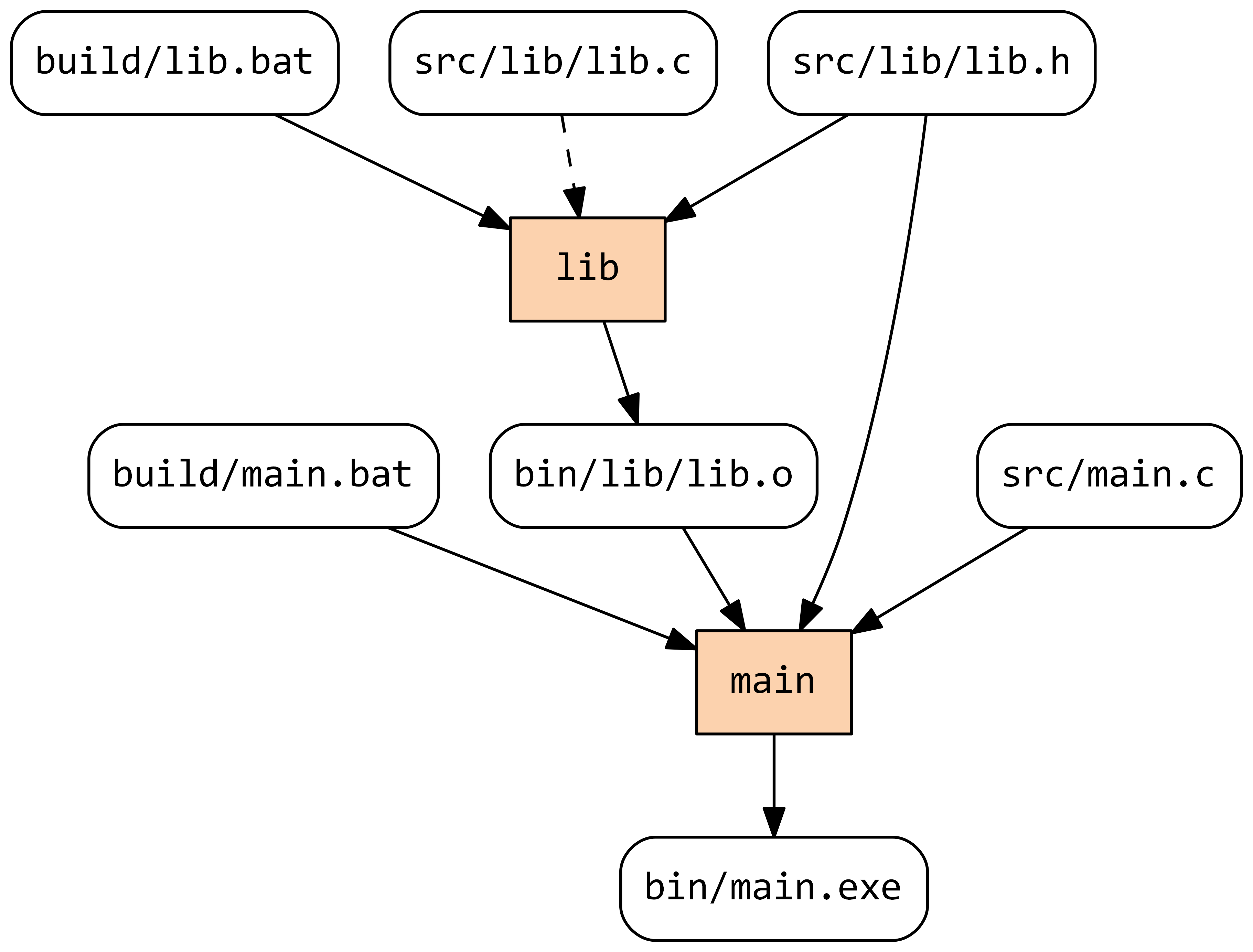
As you can see, both tasks are now marked as out-of-date: lib’s direct input has changed, which transitively also affects main. Let’s Stroll:
$ stroll build Executing build/lib.bat... Done
Stroll has rebuilt the library but the file bin/lib/lib.o didn’t change, thus restoring the up-to-date status of the task main.
Finally, to clean up after our experiments, let’s create a new task clean and place it into a different directory: clean/clean.bat.
$ cat clean/clean.bat rm bin/lib/lib.o rm bin/main.exe $ stroll clean Executing clean/clean.bat... Done
The corresponding dependency graph shows two outputs — the deleted binary files.
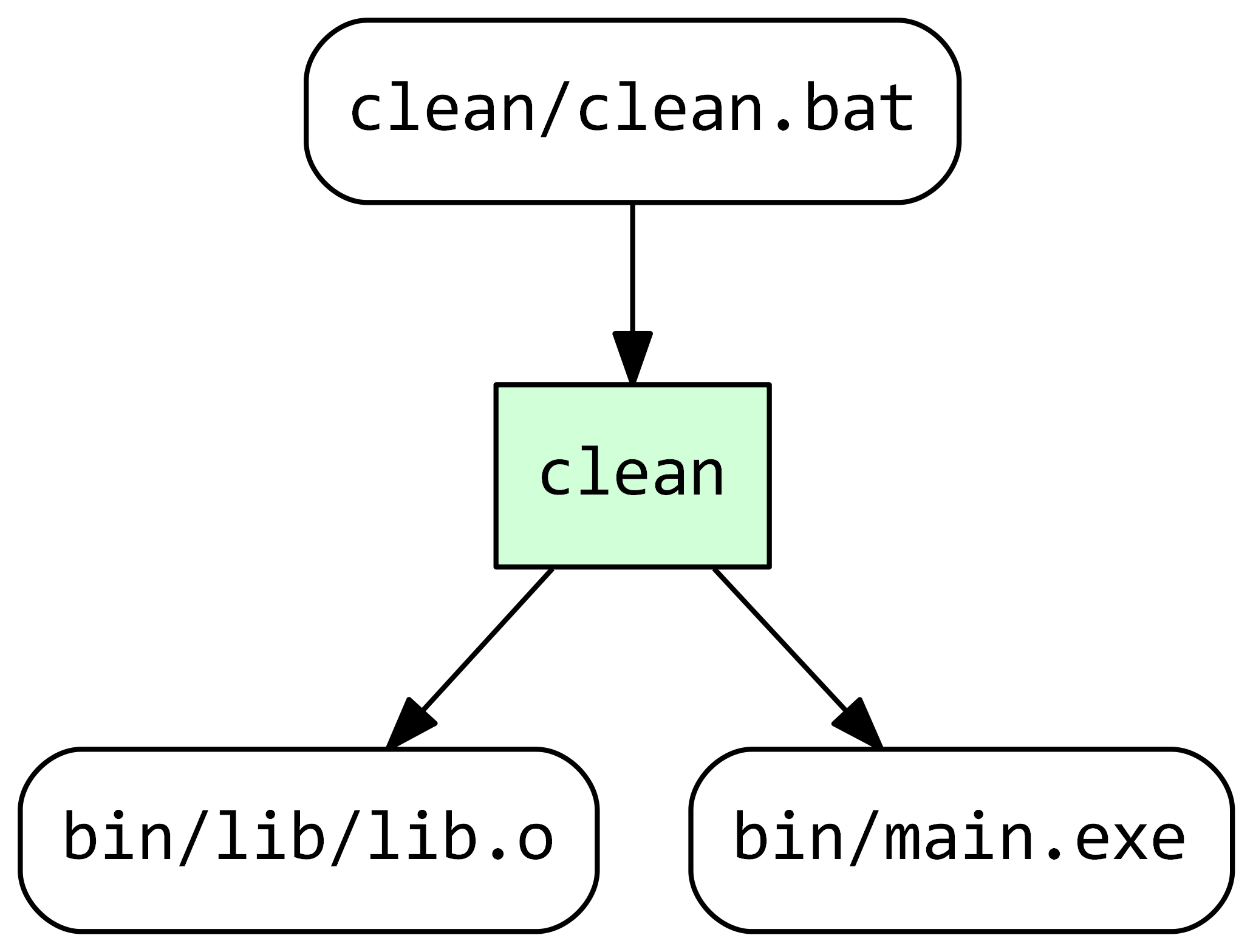
As you might have noticed, Stroll uses directories as collections of build tasks related to a common build target. To build a target we simply run Stroll in the corresponding directory. If you’d like to build just a single task from a directory, you can specify the full path, for example:
$ stroll build/lib.bat Executing build/lib.bat...
This executes the lib task (regardless of its current status). Note that the main task is currently out-of-date because clean deleted its output:
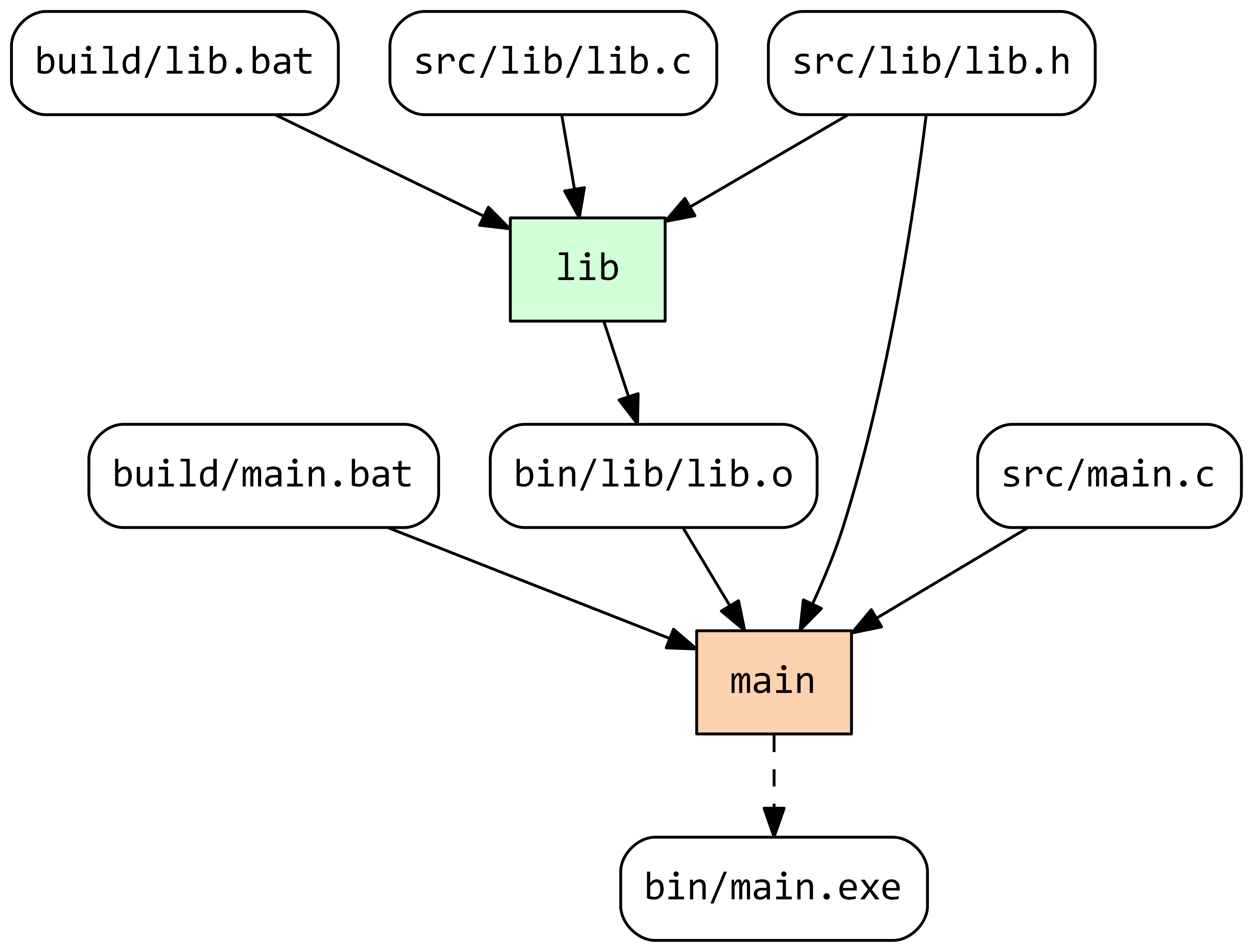
To complete the build, run stroll build, which will execute only the main task, as desired.
Challenge: Try to orchestrate a situation, where Stroll would execute one of the tasks twice, hence demonstrating that Stroll is not a minimal build system.
Under the hood
Stroll is implemented in ~400 lines of Haskell (including comments) and uses the following libraries in addition to the standard ones:
- Shake’s cmd function is used to execute build tasks tracking their file accesses. This relies on Shake’s support of the fsatrace utility.
- The algebraic graphs library Alga is used for graph construction, traversal and visualisation.
- Libraries cryptonite and yaml are used for computing file content hashes and serialising/deserialising YAML files.
Many thanks to everyone who contributed to these projects!
You are welcome to browse the source code of Stroll and/or play with it, but be warned: it has a few serious limitations (discussed below), and I’m not sure they will ever be fixed.
Limitations
Stroll is fun and I consider it a successful experiment but the current implementation has a few serious limitations:
- The fsatrace utility does not track reads from non-existing files, which means Stroll cannot determine that a task is out-of-date because a file that was previously missing has now appeared. Directory scans are not tracked either, that’s why I didn’t use a command like rm -rf bin/* in the clean script. A model of Stroll with ideal tracking that is free from these limitations is available here.
- Although fsatrace can track file movement, e.g. mv src dst, Stroll does not yet support it and terminates with an error if detected.
- The current implementation is completely sequential, i.e. build tasks are executed one by one. It’s possible to make Stroll parallel, but it’d require quite a bit of engineering. I might do it someday.
- Stroll is not a cloud build system although it’s possible to make it one by adding shared storage of artefacts keyed by their hashes. For more details see the Build Systems à la Carte paper.
Final remarks
One interesting aspect that I haven’t demonstrated above is how one can mix and match different languages when writing individual build tasks. For example, we could use Shake for compiling C source files into object files. Note that Shake itself is a build system that maintains its own state, but it still works out just fine: if Shake decides to rebuild only one object file (since others are up-to-date) Stroll can safely remember this decision — as long as all input files are the same and the Shake’s database is unchanged, we can assume that the results produced by Shake previously are still valid. This means that even though Stroll’s task granularity may be quite coarse (e.g. one task for 100 object files), these coarse-grain tasks can benefit from fine-grain incrementality and parallelism supported by other build systems, such as Shake. And if you happen to have two existing build systems written in different languages you don’t need to rewrite anything: you can compose your legacy build systems simply by placing them into the same directory and using Stroll.
Unusually, Stroll can cope with cyclic task descriptions, where a few build tasks form a dependency cycle, as well as with build tasks that generate new build tasks! Stroll simply keeps building until reaching a fixed point where all tasks are up-to-date.
Stroll does not fit the modelling approach from the Build Systems à la Carte paper, where build tasks have statically known outputs: Stroll supports both dynamic inputs and dynamic outputs. I conjecture that such build systems cannot be minimal, i.e. they fundamentally require a trial and error approach used by Stroll, where unnecessary work may be performed while discovering the complete dependency graph.
Acknowledgements
I’ve been thinking about this idea for a while and had many illuminating discussions with Ulf Adams, Arseniy Alekseyev, Jeremie Dimino, Georgy Lukyanov, Neil Mitchell, Iman Narasamdya, Simon Peyton Jones, Newton Sanches, Danil Sokolov, and probably others. A few people in this list have been sceptical about the idea, so I do not imply that they endorsed Stroll — I’m merely thankful to everyone for their insights.
Assuming you track files opened with ptrace or equivalent, another story would be to block during file access when accessing one of the files in your blackbox list while kickstarting the resource being produced by another task. You’d incur dependency-chain-depth additional process residency, but avoid “restarts” completely. You still likely wind up with issues with processes that list all of the files in a give directory and process them, though.
I track file accesses using Shake’s function `cmd` that does all boring plumbing so that it’s just one line of code for Stroll:
https://github.com/snowleopard/stroll/blob/722c77faed2f7e6ced28035be13ae4636604032a/src/Development/Stroll/Script.hs#L33
Shake’s `cmd` doesn’t support suspension but, in principle, it would be interesting to see how a suspending version of Stroll would work out.
There are a few tricky cases, although admittedly they are somewhat contrived. Things are particularly complicated during the first run where no dependency information is available and Stroll, therefore, needs to poke the scripts blindly.
* If you are unlucky with the build order, it’s possible to get into a situation where you need to suspend N-1 tasks (out of all N), exhausting memory.
* More strangely, there may be situations where all N tasks are suspended, which would be a deadlock unless we are prepared to start letting them go one by one, hoping that one of them doesn’t crash but recovers from the missing file it was blocked on and produces an output that the other tasks were waiting for.
(The situation when a task terminates successfully despite failing to read from one of the input files is not that uncommon I think, so always suspending a task on a read may be suboptimal.)
The restarting approach seems simpler and more robust, especially for the first run. It comes with a quadratic overhead in the worst case, but I think the typical case would be just constant.
I’m wondering if you’re aware of https://github.com/ndmitchell/rattle? It seems to be an implementation of a similar idea by the author of Shake.
Yes, I’m aware of Rattle. My understanding is that it’s very similar to Fabricate: it tracks file accesses of build tasks but requires the user to specify the order of task execution upfront. Stroll figures out the build order automatically.
Talking about Rattle and Fabricate with Neil was one of the motivations behind this experiment 🙂
Very interesting! One question I have is that, if there is a version of Stroll that doesn’t have the tracing limitations, as you pointed to here (https://github.com/snowleopard/build/blob/3cc873c3d30615a60757be1424bef31d892cd0b9/src/Build/Task/Opaque.hs), I suppose there was something that prevented you from using this approach in Stroll?
(Apologies for replying so late! For some reason I didn’t receive a notification about your comment.)
I can’t really use the linked approach in a real build system like Stroll, because real build rules need to execute external tools (such as compilers) that directly operate on the file system, i.e. these tools wouldn’t want to use my Get and Put callbacks!
Perhaps, it’s possible to somehow intercept all file access of external tools, essentially wrapping them in some kind of a file system monad, but I haven’t tried that yet. Sounds like a fun project though!
Amazing read, btw! Just curious, have you had the time to look at Riker? it claims to (in some cases) achieve builds comparable to Make.
* I would love to know what you think about their approach. It seems they are the closest in this space to a fully scalable solution. Do you think it’s a minimal solution?
* Do you think using ptrace (with filters) could offer quicker reads than fsatrace?
* Did you try to measure the performance of Stroll against some other projects?
Thanks!
Yes, I know about Riker and talked to the authors. The main idea behind Riker is lovely. I haven’t tried Riker on any real-life codebase, so I don’t know how well it works in practice, but I hope to try it someday.
> Do you think using ptrace (with filters) could offer quicker reads than fsatrace?
Maybe. I only tried fsatrace so far, because it was conveniently packaged in the Shake library. Do you think ptrace would be faster?
> Did you try to measure the performance of Stroll against some other projects?
Sadly, I haven’t really had time to try Stroll in practice. For now, it’s just a curious experiment, waiting to be turned into a usable product. But trying Stroll is definitely on my ever-growing to-do list!
It’s not entirely clear how the dependency graph informs the build process if you are also tracking file accesses with fsatrace
The dependency graph (that may be available from the previous build) is useful for speculating about the ordering of tasks, e.g. for speeding up builds using parallelism. When dependencies change rarely, simply following the dependency graph from the previous build is fine — in those cases, tracing is only used for verifying that our knowledge is still correct.