Following on from our annual review of data.ncl this post highlights some key statistics from our ePrints repository where researchers share their publications.
Headline stats for 2020
5086 new publication records added (total of 124,957)
2989 new full text publications made available (total 26,582)
Author profile pages were also some of our most popular pages, so we’d encourage researchers to keep their publication list is up-to-date.
Adding publications to ePrints makes them eligible for REF, but also means they are more visible and can have more impact. We optimise ePrints for research discovery and syndicate content to aggregation services such as CORE and unpaywall. That helps people find free versions of research that would otherwise be inaccessible to them as well as making text and data mining more feasible.
Our aim for 2021 is to increase the proportion of research outputs we make open access in ePrints. That will be helped by our new transformative agreements with publishers that make open access free for our authors and by funder policies like that of the Wellcome Trust and Plan S that increasingly mandate this.
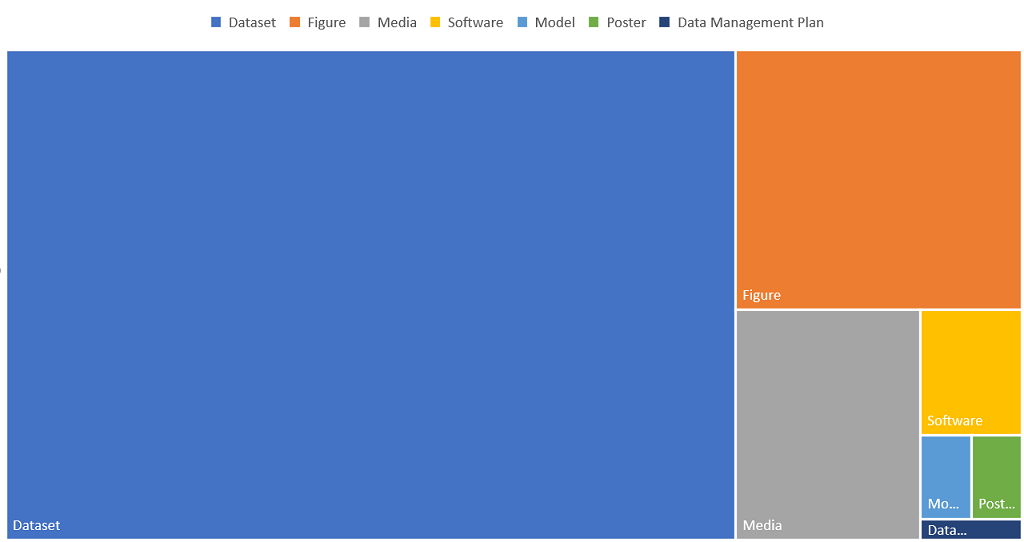
This has been the first full calendar year data.ncl has been available for our researchers to archive and share data. And in the spirit of best of 2020 articles on film, TV shows and music I have dug into data.ncl’s usage statistics to pull out the headlines.
360 data deposits (718 in total)
118 different researchers archiving data (174 in total)
154,630 views
47,190 data downloads
Our top three datasets based on views and downloads in 2020 were:
David Johnson, PGR in History, Classics and Archaeology, has followed up his post on rethinking what data is with his thoughts on data sharing. We are keen to hear from colleagues across the research landscape so please do get in touch if you’d like to write a post.
But if I wanted the text that much, the odds are good that someone else will, too, at some point.
Recently I wrote about how my perceptions of data underwent a significant transformation as part of my PhD work. As I was writing that piece, I was also thinking about the role data plays in academia in general, and how bad we are at making that data available. This is not to say we aren’t really great at putting results out. Universities in this country create tremendous volume of published materials every year, in every conceivable field. But there is a difference between a published result and the raw data that created that result. I am increasingly of the mind that we as academics can do a much better job preserving and presenting the data that was used in a given study or article.
It’s no secret that there is a reproducibilitycrisis in manyareas of research. A study is published which points to an exciting new development, but then some time later another person or group is unable to reproduce the results of that study, ultimately calling into question the validity of the initial work. One way to resolve this problem is to preserve the data set a study used rather than simply presenting the final results, and to make that data as widely available as possible. Granted, there can be serious issues related to privacy and legality that may come into play, as studies in medicine, psychology, sociology, and many other fields may contain personal data that should not be made available, and may legally need to be destroyed after the study is finished. But with some scrubbing, I suspect a lot of data could be preserved and presented within both ethical and legal guidelines. This would allow a later researcher to read an article, and then actively dig into the raw material that drove the creation of that article if desired. It’s possible that a reanalyses of that material might give some hints as to why a newer effort is not able to replicate results, or at least give clearer insights into the original methods and results, even if later findings offers a different result.
In additional to the legal and ethical considerations, there are other thorny issues associated with open data. There is the question of data ownership, which can involve questions about the funding body for the research work as well as a certain amount of ownership of the data from the researchers themselves. There may also be the question of somebody ‘sniping’ the research if the data is made available too soon, and getting an article out before the original researchers do. As with textual archives, there can also be specific embargoes on a data set, preventing that data from seeing the light of day for a certain amount of time.
Despite all the challenges, I still think it is worth the effort to make as much data available as possible. That is why I opted last year to put the raw data of my emotions lexicon online, because to my knowledge, no one else had compiled this kind of data before, and it just might be useful to someone. Granted, if I had just spent the several weeks tediously scanning and OCRing a text, I may be a little less willing to put that raw text out to the world immediately. But if I wanted the text that much, the odds are good that someone else will, too, at some point. Just having that text available might stimulate research along a completely new line that might otherwise have been considered impractical or impossible beforehand. Ultimately, as researchers we all want our work to matter, to make the world a better place. I suggest part of that process should be putting out not just the results we found, but the data trail we followed along the way as well.