Earlier this year, I was very fortunate to have the opportunity to attend the 20th International Digital Curation Conference (IDCC) in Zagreb, Croatia. The IDCC “is an established annual event with a unique place in the digital curation community, reaching out to individuals, organisations and institutions across all disciplines and domains involved in curating data and providing an opportunity to get together with like-minded data practitioners to discuss policy and practice” (Digital Curation Centre, 2026).
It was particularly humbling and inspiring to see more than 200 colleagues from institutions across the world who proactively try to improve not only open research practice, but the support we give researchers in engaging with these practices. The theme for this year’s event was AI, austerity, and authoritarianism: contemporary challenges in digital curation. The posters and presentations are openly available in the IDCC26 Conference Materials Zenodo collection.
This year, the keynote talks were very inspiring. During the opening talk, Antica Čulina spoke passionately about open research practices such as preregistration, open data, open code and preprints. It was discussed whether they can be truly and sustainably achievable, while considering the infrastructure necessary, the culture supporting them and the incentives that would stimulate engagement.
The closing talk encouraged librarians and other people who curate knowledge to be resilient when facing difficult times, funding uncertainty and authoritarianism. Lynda Kellam and Mikala Narlock delivered a powerful talk about the Data Rescue Project, reminding us of our individual and collective responsibilities as curators or creators of knowledge. It was suggested that we may need to change the way we work. They advocated for “embracing redundancy” of files and that duplicating work and having more than two back-ups can sometimes prove beneficial.
Automation
Using new technologies to streamline processes
As you can probably imagine, many sessions discussed making the work of data curators, or researchers, more efficient through automation, either with innovative programs, or with AI. Regarding the use of AI, it was questioned whether existing open-source or commercial tools should be trusted. As an alternative, the use of in-house AI tools was also discussed. One such talk among many was Enhancing the Benefits of Machine-Actionable DMPs with Generative AI.
Who will automation help?
A matter for debate is whether using such tools would actually save us time, or simply change our process of ensuring that the output is sufficiently robust. Who would it even save time:
the person writing a data management plan, with the use of AI; or using AI to review their own plan before a submission?
or the person reviewing it?
Avoiding duplication
Researchers are busy people. A preregistration, ethical review and data management plan, often contain the same pieces of information that were used in a grant application. Are researchers expected to rewrite the same information? Interoperability of files and systems, and the capability to harvest relevant information for the right purpose, were recommended as improvements to current processes. Colleagues from the Eindhoven Institute of Technology described a tool that extracts structured metadata based on a user-defined schema, from research proposals, to populate data management plans.
Other tools
However, automation doesn’t always require AI. One informative talk delivered by a colleague from the UK Centre for Ecology & Hydrology (UKCEH), who host the Environmental Information Data Centre (EIDC), showcased a tool they designed to help check research data compliance with the FAIR principles. The File Check Assistant “tests CSV data files for basic principles of re-usability, such as file structure and encoding, and helps guide users towards good practice”. This sounds particularly useful for large files as it can quickly identify if values are missing or are out of the defined range. While this tool was created to tackle issues with one specific type of file, it made me dream of tools that could help with a variety of other datasets: from missing metadata, to checking if interview transcripts are sufficiently desensitised.
Experts, communication and silos
The academic world is a large community, and each university is a community itself. Within a university there are many specialised sub-communities. They work independently from each other and develop their expertise in isolation. They are known as ‘silos’. Researcher silos are unique in their needs, and specialised in their solutions and protocols. Consequently, their research data practices will be unique from planning, to documenting, to sharing.
Similarly, professional services teams who support research are also siloed and focus on their individual areas of expertise. Among such teams, colleagues responsible for research data management offer general advice intended to be relevant to as many researchers as possible.
Colleagues from the Swedish University of Agricultural Sciences (SLU) advocated for better collaboration between academic and professional services silos. The SLU solution involved widening the use of their library’s online enquiry service, so that other university teams would also receive relevant queries through it. This facilitated smarter collaboration and knowledge sharing between support teams. Sharing knowledge and tailoring existing solutions to help others can be powerful tools in overcoming challenges and resource shortages with the aim of making our research outputs FAIR.
Data management plans (DMPs)
DMPs are always mentioned when two research data professionals are in the same room. This might sound cynical, or be perceived as a joke, but they are mentioned because they are a crucial part of the research process, they are time consuming and difficult to get right. It was eye-opening to see how differently they can be approached by different universities. Some of us strongly encourage their use. Others mandate them for all research projects. In some institutions, a small number of support staff, like me, review them on request. In other places, this responsibility is shared to supervisors in the case of postgraduate research projects.
An entirely different element is the choice of tools and mechanisms that we use to write and review DMPs, and I won’t refer to genAI tools this time. At Newcastle University, we use DMPonline, employing a generic template from the Digital Curation Centre, along with many funder-specific templates, each with detailed guidance. Some dynamic alternatives to DMPonline exist, giving users templates that tailor themselves based on previous answers. In theory, this should ensure that questions are as relevant as possible to researchers that might struggle with static templates. The alternatives discussed are Data Stewardship Wizard and FAIR Wizard. The former is an open-source tool, whereas the latter uses the former’s engine.
Another interesting approach employed templates provided in text documents. The documents are simple and are not overwhelming, as the guidance exists separately, on the website. Researchers are given the opportunity to request feedback for their DMPs by submitting a request form via the library’s online enquiry service. All the options above are interesting and have their merits. This made me reflect on whether one of them would be better at bringing together advice, support and guidance, while maintaining relevancy to as many experts as possible, in a variety of disciplines. What is the best way to incorporate definitions, encourage reflection and promote inclusion for colleagues who may not be familiar, or comfortable, with the language that has become standard in research data management circles?
Other takeaways and applications
Data access statements that use standardised language
Something close to my heart (or my day-to-day job) is the transparency of data access statements. It was emphasised by colleagues at the University of Bristol how important it is to have data access statements that use standardised language. It was suggested that we should use a taxonomy similar to CRediT. At a local level, I will continue to highlight the importance of data access statements, the need for enhanced clarity regarding the level of access to the data, persistent identifiers (such as DOIs) and additional information needed for accessing research data. Encouraging the research community to have clearly worded data availability statements in publication metadata will be a great step forward in enhancing data FAIRness and therefore, research transparency.
Key decision moments in the research data lifecycle
Another takeaway is João Aguiar Castro’s work, which aims to “enhance the usability, interpretability, and long-term value of DMPs” for all involved in research. João’s framework inspired me to assess the messages and guidance I provide in training and one-to-one consultation meetings regarding the level of detail required for a data management plan. While most of us already strive for this, using clearer language and digging deeper into researchers’ needs at different stages of their projects will most likely lead to more relevant conversations and useful DMPs.
Networking and community
The IDCC was such a welcoming event. The attendees are all open to sharing knowledge and improving research transparency: it comes with the job description. The community is one that relies in cross-institution collaboration because at our respective institutions there are so few of us. And we are all continuously learning.
I am still working through my notes from the conference and I hope, in the near future, to arrange meetings with some of the colleagues I met. We are already exchanging ideas via LinkedIn or email, and some attendees have been sending me additional information that I had asked for.
Me, receiving the award for the most active attendee, a very kind gesture from the organisers since I did not present a paper, or a poster, at this conference
Zagreb
Art Pavilion in Zagreb, with fountain
I was very lucky to spend some time as a tourist in Zagreb as well. My odd brain found an interesting link between the theme of the IDCC and Zagreb, a city full of museums, some of which rather serious, others rather whimsical. It felt serendipitous that this year’s event, focused on contemporary challenges in digital curation took place in a city that is so focused on remembering and preserving the knowledge of the past. One of the several museums I visited was truly memorable. The Museum of Lost Tales provided a unique look into the folklore and mythology of Croatia. Using allegory in the beginning, it showcased a fantastic creation myth that was sometimes similar to Norse mythology. For example, there is a world tree (Stablo svijeta), and a fierce and formidable warrior god of thunder (Perun), with red hair and beard.
Worlds connected through the World Tree
Deities of Croatian mythology around the World Tree
The OA policy applies to journal articles and conference proceedings with an ISSN that are published after 1 January 2021. It does not apply to any other research outputs, such as chapters, books, data, etc, although REF encourages researchers to move beyond the minimum requirements and apply open practices where possible to all outputs.
For inclusion in the REF OA submission, a version of the published article must be made open access, i.e. deposited, made accessible and discoverable, within the expected timeframes. The guidance for outputs published after 1 January 2026 has been updated, and the table below summarisies the key details.
Outputs made immediately open access on publication, provided they meet the deposit, access and licence criteria, will meet REF OA requirements. Note, there is no expectation that additional open access publication costs are required to meet REF 2029 OA policy requirements.
Newcastle University Guidance
We advise that Newcastle University authors continue to deposit their AAM in our institutional repository as soon as possible after acceptance. Following deposit, the open access team will review uploaded manuscripts and contact authors to discuss any issues in meeting the open access requirements for REF. In line with the University Research Publications & Copyright Policy, for any articles published after August 2023, the AAM will be made available open access in the University’s repository under a CC BY licence, on the article publication date, unless an embargo is required (see above for permitted embargo periods).
Detailed instructions of the policy requirements and how to make your paper REF eligible are available on our Open Access for REF page. Some exceptions to the policy are permitted for outputs that do not meet the OA requirements, details of how to apply for these are also shown on that page.
For more information or to arrange a discussion, please contact openaccess@ncl.ac.uk.
*The author accepted manuscript (AAM) is the version after peer review and containing all academically necessary changes, but before publisher copy-editing, proofing and typesetting of the peer-reviewed accepted manuscript.
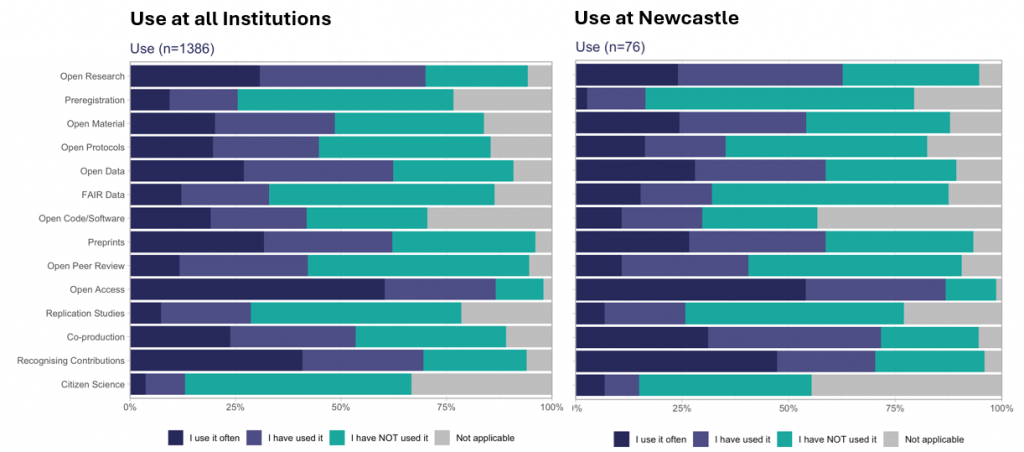
The UK Reproducibility Network (UKRN) has published the findings of its 2025 Open Research Programme (ORP) Survey, providing detailed insights into the prevalence open research practices such as data sharing, preregistration, open code, and open access publications, alongside attitudes and perceived barriers to open research adoption from across UK higher education, including Newcastle University.
This post presents a summary of findings from the aggregated national survey and reflections on our institutional results at Newcastle University.
Awareness and Use: Awareness of OR practices is high overall, but uptake varies. Open access is near-universal (99% awareness, 86% use), while preregistration and citizen science awareness/use are lower (55%/25% and 66%/13%, respectively). Awareness of FAIR data is the lowest of any OR practice at 51%. Disparities between awareness and use are greatest for replication studies, citizen science, and open code/software, suggesting persistent barriers.
Disciplinary and Career Differences: Quantitative and mixed-methods researchers report higher engagement than qualitative researchers, and uptake is generally greater in scientific disciplines than in arts and humanities. Senior researchers show higher awareness and use, though junior and mid-career researchers express strong motivation to engage more.
Attitudes: Most respondents view OR as useful (80%), but only 42% feel their institution provides adequate training. Only 18% of respondents engaged with OR in hiring and promotion of staff.
Facilitators: Practical enablers—guidance, infrastructure, time allocation—are prioritised over cultural drivers.
Results from Newcastle
Our survey was conducted between May and July 2025. We invited responses from a random sample of 10% of research colleagues and PGRs, stratified for representation across disciplines and career levels. It was sent to 503 recipients and 77 responses were received (15% response rate). Respondents represented 19 disciplines, with 31.2% primarily using quantitative research methods, 22.1% qualitative and 41.6% both. 36.4% declared their career stage as ‘junior’, 28.6% as ‘mid’ and 32.5% as ‘senior’.
Our results showed similar trends to those in the overall survey. Awareness of OR practices was relatively high overall. It was generally higher among those using quantitative methods compared to those using only qualitative methods, with the exception being co-production. Awareness was also generally higher in health and biological sciences and physical sciences disciplines than in arts and humanities and social sciences.
Use of open research practices largely mirrored awareness. Open access publication is used almost universally. Co-production, recognising contributions, preprints and open data are also widely used. Preregistration, replication studies and citizen science are less commonly used. Sharing of code/software is perhaps lower than expected given its broad potential applicability and relatively high levels of awareness.
Attitudes to open research were broadly positive with most respondents stating they feel it is useful and that they wished to engage more with open practices. However, we still have some work to ensure appropriate training, support and recognition across methodologies and disciplines before open research can become normalised.
We will use these findings to further improve our open research training and support and to target new interventions where they are needed to achieve that.
If you’d like to find out more you can download a PDF of our full institutional report.
Gabriel is an Open Research Champion for School of English Literature, Language and Linguistics. After attending an academic conference in Barcelona we provided some external funds to support a short extension to visit a colleague at Universitat Pompeu Fabra to discuss running an Open Access journal. Here’s what he learned…
In my visit to Barcelona, I integrated a conversation about Open Access and Open Research with Professor Louise McNally, Co-Editor-in-Chief of Semantics & Pragmatics, a leading Open Access journal for semantics and pragmatics research.
“Semantics and Pragmatics is a fully open access journal. All content is freely and immediately accessible to readers under a liberal CC-BY license. The journal is supported by the Linguistic Society of America, the Massachusetts Institute of Technology, and the University of Texas. Authors do not pay publication charges (APCs) nor submission charges. Authors retain full copyright and all rights of reuse.”
I wanted to hold a meeting with her as a fellow linguist to discuss their approach to open access, since in a couple of months I will become Co-Editor-in-Chief of Glossa: a journal of general linguistics, the leading journal in linguistics and a pioneering Open Access journal in the field. I wanted to benefit from her experience and expertise in this area. As a result of our conversation, I got some pieces of advice as to what areas are key when leading an Open Access journal.
The main component is sustainability in several respects (financial, production, administrative). In Louise’s opinion, it is fundamental to think ahead especially to editorial/management transitions, such as the ones I am currently involved in. In this regard, one has to make sure that there is time to familiarize new editors with how things have been done, so that any major policy decisions that are made can be discussed with them.
Further, it is very important to be proactive in that one should take advantage of whatever venues one has to explain to libraries, funding agencies, among others. Importantly, efforts should be made to get the home institutions of the editorial team to support the journal. In this sense, this is a joint effort to ensure that the journal survives in the medium to long term.
More generally, what this means is that the work that is done needs to be visible. Thus, it is key to further promote and support open access publishing models such as Diamond Open Access and Subscribe to Open.
Overall, these efforts constitute a very specific set of efforts to promote Open Research as related to Open Access journals, which, ultimately, shape the future of linguistics as a field where knowledge and ideas have the opportunity to flow freely—not being tied to paywalls. I will certainly integrate all these pieces of advice in my new role!
If you are involved in research, even to a small extent, you may benefit from attending training offered by the Library Research Services team.
On the 12th February 2026, between 11:00 and 13:00, there will be an online, practical training workshop for research data management. Attended by over 60 researchers in the last year, ‘Introduction to Writing a Data Management Plan’ is suitable for colleagues new to research (in various roles) and for those of you who may wish to refresh their memory and renew their day-to-day data practices.
Suitable for all disciplines, this session encourages you to think about what underpins, helps others understand, or validates your research claims and publications. It will include a live demonstration of DMPonline, a web-based tool designed to help you write, or update, your data management plan and you will have the opportunity to start outlining your own plan. We will provide considerations for the individual sections of a data management plan (DMP):
Outlining and detailing your data.
Data collection methods, consistency and quality assurance.
Metadata and documentation. How will you ensure your continuous understanding of your own work. How will others be able to make sense of it?
Ethical and legal considerations.
Short-term, active project storage.
Long-term storage, sharing and preservation. This will include information about the university’s repository, finding alternative repositories and staying compliant with funder requirements.
These training sessions are run a few times each academic year and we try to provide a mix of in-person and online training. For more information about the support we provide, please visit our website.
Coincidentally, this training session will take place during everyone’s favourite celebration, Love Data Week. So, what better time is there to think about your research data?
Are you looking for advice and information on open access or managing publications? Come to one of our monthly drop-in sessions and meet members of the Library Research Services team, who will be happy to answer questions on:
Copyright and licencing issues relating to your publications
Uploading your publications to our repository and REF
Whether you’re a seasoned researcher, student or simply keen to explore the possibilities within open access, this session offers a welcoming space to ask questions, gain insights and delve deeper into the realm of open access.
These are informal sessions, however, registration is required for you to receive the online teams link.