This December, you can come and chat with members of the Library Research Services (LRS) team at our pop-up event (12.00-14.00) on the 11th at The Atrium, Urban Sciences Building.
This November, you can come and chat with members of the Library Research Services (LRS) team at one of our pop-up events (12.00-14.00) on the 5th (Medical School Foyer) and 12th (Henry Daysh Café Space).
Library Research Services is excited to announce a series of informal Pop-up Sessions across campus in November and December. These sessions are designed to showcase the wide range of services we offer. We warmly invite academics and researchers to join us with any questions they may have about open access publishing, data management, or any specific open research queries. Below, you will find a full list of our locations and dates.
Tuesday, 5th November, 12pm-2pm: Medical School Foyer
Tuesday, 12th November, 12pm-2pm: Henry Daysh Café Space
Wednesday, 11th December, 12pm-2pm: The Atrium, Urban Sciences Building
Don’t worry if you miss us this time—you’ll have the opportunity to speak to us again in the new year. You can also contact us anytime at lrs@ncl.ac.uk
Following the success of our Open Access Support Sessions earlier in the year, our monthly informal sessions will be returning from September.
Are you looking for advice and information on open access or managing publications? Come to one of our monthly drop-in sessions and meet members of the Library Research Services team, who will be happy to answer questions on:
Publishing open access
Understanding research funder policy requirements
Copyright and licencing issues relating to your publications
Uploading your publications to MyImpact
Whether you’re a seasoned researcher, student or simply keen to explore the possibilities within open access, these sessions offer a welcoming space to ask questions, gain insights and delve deeper into the realm of open access.
Each session will focus on a specific area and how this relates to open access:
During the summer months data.ncl, Newcastle’s research data repository, reached over 500,000 views from datasets and code archived from researchers across the University. Reaching this milestone affords us the opportunity to take stock of how far we have travelled in openly sharing data as data.ncl was only launched in spring 2019.
It equally provides an indication of the reach data can have when it is archived and becomes findable, searchable and citable. Records in data.ncl have been viewed from as far away as Chile and New Zealand while the three countries who view and access data most frequently are USA, Netherlands and the UK – showing the global and national interest in research created at Newcastle University. In addition to views, data.ncl has enabled 215,000 downloads and preserves over 1200 records for future reuse.
“The long-term archiving and sharing of datasets through data.ncl is a significant part of our support for Open Research. Seeing datasets being viewed, accessed and reused shows there is real value in giving data a second life through data.ncl” said Professor Candy Rowe, Dean for Research Culture and Strategy. Professor Brian Walker, Pro-Vice-Chancellor for Research Strategy and Resources added: “Reaching this milestone shows Newcastle University is committed, along with UK government and other research funders, to the conduct of Open Research that is available to and used by as many people as possible for as long as possible”.
All researchers and PGRs can freely archive and publicly share data from their research through data.ncl. Archived data obtains its own DOI (Digital Object Identifier) for inclusion in research outputs, including publications. To help increase engagement and impact archived data is indexed by Google Scholar and Google Dataset search. Data collections can also be created to group together data records produced from a project or research theme with its own DOI to increase discovery. This can include records of data held in discipline specific repositories to create a full showcase of the data produced by a research project.
The Research Data Service has reviewed and approved hundreds of datasets and these are a few highlights:
The Coral Spawning Database brings together a huge international effort that includes over 90 authors from 60 institutions in 20 countries to openly share forty years of coral data in one place for the first time. The intention is for this database to grow over time so the data isn’t set in stone and can be added to as the research progresses. Dr James Guest said: “Coral reefs have been declining in health for decades and are severely threatened by climate change. It is, therefore, more important than ever to share large datasets on these ecosystems so that they can be used to guide management of reefs in the Anthropocene”. James added: “When we were looking for a suitable data repository for the Coral Spawning Database, data.ncl was the obvious choice because it was so user friendly and has excellent support from the Research Data Service at Newcastle University”.
Through National Lottery Heritage Fund, Dr Nicky Garland mapped and shared a number of features of Hadrian’s Wall including forts, towers, and road systems. The aim was to make the data open and accessible to allow researchers and the wider community to engage with Hadrian’s Wall and its conservation and research. The data records are proving to be very popular and are clearly supporting the aims of the WallCAP project. “In terms of our project decision to use data.ncl – it was a no-brainer! WallCAP will generate a considerable amount of data and we want that data to be readily accessible. Having a secure digital archive that provides DOIs that can be easily incorporated into academic publications is not only convenient, but essential in this era of data-proliferation” said Dr Rob Collis, Project Manager.
The Dental Micromotor Handpiece Dataset was one of the first open data examples of Newcastle University responding to the Covid-19 Pandemic. James Allison, Clinical Fellow, explained: “Our project looked at how we can use novel dental drill designs to reduce the amount of aerosol produced during dental procedures. This is important because concerns over transmitting viruses in these aerosols caused dental services to shut down during the Covid-19 pandemic. Our work showed that these drills produce less aerosol and therefore reduce this risk, allowing them to be safely used in dental practices. This also helped dental students get back to treating their patients at the School of Dental Sciences and in other institutions in the UK. We felt it was important to share our data on data.ncl so that it was available to other researchers looking at the same problem, and also to those developing guidance and policy documents to inform their decisions.”
Ali Alammer was a PhD researcher who shared his underpinning code for a biologically inspired machine vision model (En-HMAX), which rapidly processes 2D images with minimal computational requirements. Ali explained: “With a hierarchy of only six processing layers, the model was capable of extracting formative and unique representation to objects and scenes. It had also achieved comparable performances to existing state-of-the-art architectures including deep learning. I archived the code for research reproducibility purposes as it has a wide range of applications that includes surveillance and robotic vision.”
The Research Data Service runs data.ncl and supports researchers in planning, managing and sharing research data. For further information please visit the research data management website or contact rdm@ncl.ac.uk.
To researchers’ credit across the globe the amount of data being shared is growing and this will only increase over time as open research becomes ubiquitous. There are significant benefits to data sharing including increased rigour, transparency, and visibility.
But this post isn’t going to get blogged down in the benefits of data sharing as it is a path well-trodden. Instead, let’s consider that as researchers have been archiving and sharing data in archives and repositories there is a rich source of material that can be accessed, reworked, reanalysed and compared to recent data collections.
This secondary data analysis is a growing area of interest to researchers and funders, with the latter having calls focusing solely on reanalysis of data (e.g. UKRI). Accessing historic data also allows for research to be undertaken where costs are prohibitive, data is impossible or difficult to collect, and, possibly, reduce the burden on over researched populations. With the continuing challenges with collecting primary data during the pandemic there might not be a better time to consider what data is already out there.
And it is not only research that can benefit but also teaching and learning. Archived data sources can be accessed to introduce students to a fantastic range of existing data and code. Using secondary data can free students of data collection allowing them to focus on developing skills of research questions and analysis.
Based on data from re3data.org as of April 2021 there are over 2600 data repositories available for researchers to archive data, up from 1000 in November 2013. This isn’t a completely exhaustive list but is close enough to give an idea of the scale. Amongst these is our own data.ncl that now houses over 1200 datasets shared by university colleagues from across all disciplines and collected using a variety of methods and techniques.
However, finding the right dataset for your latest research project or teaching idea isn’t always straightforward. To help with that I have created guidance on how to find, reuse and cite data on the RDM webpages.
I would also be very keen to hear from users of secondary data to create case studies to inspire colleagues on this approach. If you would be interested in sharing your approach and experience, then please do get in touch.
Chris Harrison, as an astronomer who is a Newcastle University Academic Track Fellow (NUAct). Here he reflects on the good and bad aspects of reproducible science in observational astronomy and describes how he is using Newcastle’s Research Repository to set a good example. We are keen to hear from colleagues across the research landscape so please do get in touch if you’d like to write a post.
I use telescopes on the ground and in space to study galaxies and the supermassive black holes that lurk at their centres. These observations result in gigabytes to terabytes of data being collected for each project. In particular, when using interferometers such the Very Large Array (VLA) or the Atacama Large Millimetre Array, (ALMA) the raw data can be 100s of gigabytes from just one night of observations. These raw data products are then processed to produce two dimensional images, one dimensional spectra or three dimensional data cubes which are used to perform the scientific analyses. Although I mostly collect my own data, every so often I have felt compelled to write a paper from which I wanted to reproduce the results from other people’s observational data and their analyses. This has been in situations where the results were quite sensational and appeared to contradict previous results or conflict with my expectations from my understanding of theoretical predictions. As I write this, I have another paper under review that directly challenges previous work. This has been after a year of struggling to reproduce the previous results! Why has this been and what can we do better?
On the one hand most astronomical observations have incredible archives where all raw data products ever taken can be accessed by anyone after the, typically 1 year long, proprietary period has expired (great archive examples are ALMA and the VLA). These always include comprehensive meta-data and is always provided in standard formats so that it can be accessed and processed by anyone with a variety of open access software. However, from painful experience, I can tell you that it is still extremely challenging to reproduce other people’s results based on astronomical observational data. This is due to the many complex steps that are taken to go from the raw data products to a scientific result. Indeed, these are so complex it is basically not possible to adequately describe all steps in a publication. The only real solution for completely reproducible science would be to publicly release processed data products and the codes that were used both to reproduce these and analyse them. Indeed, I have even requested such products and codes from authors and found that they have been destroyed forever on broken hard drives. As early-career researchers work in a competitive environment and have vulnerable careers, one cannot blame them for wanting to keep their hard work to themselves (potentially for follow-up papers) and to not expose themselves to criticism. Discussing the many disappointing reasons why early career research are so vulnerable – and how this damages scientific progress – is too much to discuss here. However, as I now in an academic track position, I feel more confident to set a good example and hopefully encourage other more senior academics to do the same.
In March 2021 I launched the “Quasar Feedback Survey”, which is a comprehensive observational survey of 42 galaxies hosting rapidly growing black holes. We will be studying these galaxies with an array of telescopes. With the launch of this survey, I uploaded 45 gigabytes of processed data products to data.ncl (Newcastle’s Research Repository), including historic data from pilot projects that lead to this wider survey. All information about data products and results can also easily be accessed via a dedicated website. I already know these galaxies, and hence data, are of interest to other astronomers and our data products are being used right now to help design new observational experiments. As the survey continues the data products will continue to be uploaded alongside the relevant publications. The next important step for me is to find a way to also share the codes, whilst protecting the career development of the early career researchers that produced the codes.
To be continued!
Image Credit: C. Harrison, A. Thomson; Bill Saxton, NRAO/AUI/NSF; NASA.
This has been the first full calendar year data.ncl has been available for our researchers to archive and share data. And in the spirit of best of 2020 articles on film, TV shows and music I have dug into data.ncl’s usage statistics to pull out the headlines.
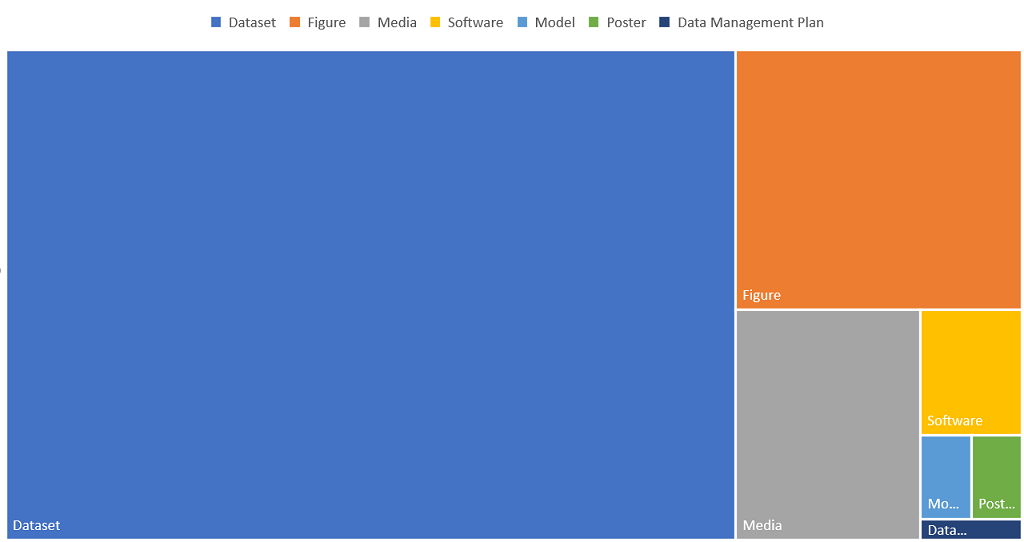
360 data deposits (718 in total)
118 different researchers archiving data (174 in total)
154,630 views
47,190 data downloads
Our top three datasets based on views and downloads in 2020 were:
David Johnson, PGR in History, Classics and Archaeology, has followed up his post on rethinking what data is with his thoughts on data sharing. We are keen to hear from colleagues across the research landscape so please do get in touch if you’d like to write a post.
But if I wanted the text that much, the odds are good that someone else will, too, at some point.
Recently I wrote about how my perceptions of data underwent a significant transformation as part of my PhD work. As I was writing that piece, I was also thinking about the role data plays in academia in general, and how bad we are at making that data available. This is not to say we aren’t really great at putting results out. Universities in this country create tremendous volume of published materials every year, in every conceivable field. But there is a difference between a published result and the raw data that created that result. I am increasingly of the mind that we as academics can do a much better job preserving and presenting the data that was used in a given study or article.
It’s no secret that there is a reproducibilitycrisis in manyareas of research. A study is published which points to an exciting new development, but then some time later another person or group is unable to reproduce the results of that study, ultimately calling into question the validity of the initial work. One way to resolve this problem is to preserve the data set a study used rather than simply presenting the final results, and to make that data as widely available as possible. Granted, there can be serious issues related to privacy and legality that may come into play, as studies in medicine, psychology, sociology, and many other fields may contain personal data that should not be made available, and may legally need to be destroyed after the study is finished. But with some scrubbing, I suspect a lot of data could be preserved and presented within both ethical and legal guidelines. This would allow a later researcher to read an article, and then actively dig into the raw material that drove the creation of that article if desired. It’s possible that a reanalyses of that material might give some hints as to why a newer effort is not able to replicate results, or at least give clearer insights into the original methods and results, even if later findings offers a different result.
In additional to the legal and ethical considerations, there are other thorny issues associated with open data. There is the question of data ownership, which can involve questions about the funding body for the research work as well as a certain amount of ownership of the data from the researchers themselves. There may also be the question of somebody ‘sniping’ the research if the data is made available too soon, and getting an article out before the original researchers do. As with textual archives, there can also be specific embargoes on a data set, preventing that data from seeing the light of day for a certain amount of time.
Despite all the challenges, I still think it is worth the effort to make as much data available as possible. That is why I opted last year to put the raw data of my emotions lexicon online, because to my knowledge, no one else had compiled this kind of data before, and it just might be useful to someone. Granted, if I had just spent the several weeks tediously scanning and OCRing a text, I may be a little less willing to put that raw text out to the world immediately. But if I wanted the text that much, the odds are good that someone else will, too, at some point. Just having that text available might stimulate research along a completely new line that might otherwise have been considered impractical or impossible beforehand. Ultimately, as researchers we all want our work to matter, to make the world a better place. I suggest part of that process should be putting out not just the results we found, but the data trail we followed along the way as well.
This is our first guest post on the Opening Research blog. We are keen to hear from colleagues across the research landscape so please do get in touch if you’d like to write a post. But the honor of debut guest blogger goes to David Johnson, PGR in History, Classics and Archaeology.
The trainings on open publishing and data storage fundamentally changed my perspective on what constitutes data.
Coming to start my PhD from a background in history and the humanities, I really didn’t give the idea of data much thought. I knew I was expected to present evidence about my topic in order to defend my research and my ideas, but in my mind there was a fundamental difference between the kind of evidence I was going to work with and ‘data’. Data was something big and formal, a collection of numbers and formulae that people other than me collated and manipulated using advanced software. Evidence was the warm and fuzzy bits of people’s lives that I would be collecting in order to try and say something meaningful about them, not something to ‘crunch’, graph, or manipulate. This was a critical misconception that I am pleased to say I have come to terms with now.
What I had to do was get away from the very numerical interpretation of the term ‘data’, and start to think in broader terms about the definition of the word. When I was asked about a data plan for my initial degree proposal, I said I didn’t have one. I simply didn’t think I was going to need one. In fact, I had already developed a basic data plan without realising what it was called. My initial degree proposal included going through a large volume of domestic literature and gathering as many examples of emotional language as I could find to create a lexicon of emotions words in use during the nineteenth century. In retrospect, it’s obvious that effort was fundamentally based in data analysis, but my notion of what ‘data’ was prevented me from seeing that at the time.
What changed my mind was some training I went to as part of my PhD programme, which demonstrates how important it is to engage with that training with an open mind. The trainings on open publishing and data storage fundamentally changed my perspective on what constitutes data. Together these two training events prompted me to reconsider the way I approached the material I was collecting for my project. My efforts to compile a vocabulary of emotions words from published material during the nineteenth century was not just a list of word, but was a data set that should be preserved and made available. Likewise, the ever-growing pile of diary entries demonstrating the lived emotional experiences of people in the nineteenth century constitutes a data set. Neither of these are in numerical form, yet they both can be qualitatively and quantitatively evaluated like other forms of data.
I suspect I am not alone in carrying this misconception as far into my academic work as I have. I think what is required for many students is a rethinking of what constitutes data. Certainly in the hard sciences, and perhaps in the social sciences there is an expectation of working with traditional forms of data such as population numbers, or statistical variations from a given norm, but in the humanities we may not be as prepared to think in those terms. Yet whether analysing an author’s novels, assessing parish records, or collecting large amounts of diary writings as I am, the pile of text still constitutes a form of data, a body of material that can be subjected to a range of data analysis tools. If I had been able to make this mind shift earlier in my degree, I might have been better able to manage the evidence I collected, and also make a plan to preserve that data for the long term. That said, it’s still better late than never, and I am happy say I have made considerable progress since I rethought my notions of what data was. I have put my lexicon data set out on the Newcastle Data Repository, so feel free to take a look at https://doi.org/10.25405/data.ncl.11830383.v1.