Neil Mitchell, Simon Peyton Jones and I have just finished a paper describing a systematic and executable framework for developing and comparing build systems. The paper and associated code are available here: https://github.com/snowleopard/build. The code is not yet well documented and polished, but I’ll bring it in a good shape in April. You can learn more about the motivation behind the project here.
(Update: the paper got accepted to ICFP! Read the PDF, watch the talk.)
In this blog post I would like to share one interesting abstraction that we came up with to describe build tasks:
type Task c k v = forall f. c f => (k -> f v) -> k -> Maybe (f v)
A Task is completely isolated from the world of compilers, file systems, dependency graphs, caches, and all other complexities of real build systems. It just computes the value of a key k, in a side-effect-free way, using a callback of type k → f v to find the values of its dependencies. One simple example of a callback is Haskell’s readFile function: as one can see from its type FilePath → IO String, given a key (a file path k = FilePath) it can find its value (the file contents of type v = String) by performing arbitrary IO effects (hence, f = IO). We require task descriptions to be polymorhic in f, so that we can reuse them in different computational contexts f without rewriting from scratch.
This highly-abstracted type is best introduced by an example. Consider the following Excel spreadsheet (yes, Excel is a build system in disguise):
A1: 10 B1: A1 + A2 A2: 20 B2: B1 * 2
Here cell A1 contains the value 10, cell B1 contains the formula A1 + A2, etc. We can represent the formulae (i.e. build tasks) of this spreadsheet with the following task description:
sprsh1 :: Task Applicative String Integer sprsh1 fetch "B1" = Just ((+) <$> fetch "A1" <*> fetch "A2") sprsh1 fetch "B2" = Just ((*2) <$> fetch "B1") sprsh1 _ _ = Nothing
We instantiate the type of keys k with String (cell names), and the type of values v with Integer (real spreadsheets contain a wider range of values, of course). The task description sprsh1 embodies all the formulae of the spreadsheet, but not the input values. Like every Task, sprsh1 is given a callback fetch and a key. It pattern-matches on the key to see if it has a task description (a formula) for it. If not, it returns Nothing, indicating that the key is an input. If there is a formula in the cell, it computes the value of the formula, using fetch to find the value of any keys on which it depends.
The definition of Task and the above example look a bit mysterious. Why do we require Task to be polymorphic in the type constructor f? Why do we choose the c = Applicative constraint? The answer is that given one task description, we would like to explore many different build systems that can build it and it turns out that each of them will use a different f. Furthermore, we found that constraints c classify build tasks in a very interesting way:
- Task Applicative: In sprsh1 we needed only Applicative operations, expressing the fact that the dependencies between cells can be determined statically; that is, by looking at the formulae, without “computing” them — we’ll demonstrate this later.
- Task Monad: some tasks cannot be expressed using only Applicative operations, since they inspect actual values and can take different computation paths with different dependencies. Dependencies of such tasks are dynamic, i.e. they cannot be determined statically.
- Task Functor is somewhat degenerate: the task description cannot even use the application operator <*>, which limits dependencies to a single linear chain. Functorial tasks are easy to build, and are somewhat reminiscent of tail recursion.
- Task Alternative, Task MonadPlus and their variants can be used for describing tasks with non-determinism.
Now let’s look at some examples of what we can do with tasks.
Compute
Given a task, we can compute the value corresponding to a given key by providing a pure store function that associates keys to values:
compute :: Task Monad k v -> (k -> v) -> k -> Maybe v compute task store = fmap runIdentity . task (Identity . store)
Here we do not need any effects in the fetch callback to task, so we can use the standard Haskell Identity monad (I first learned about this trivial monad from this blog post). The use of Identity just fixes the ‘impedance mismatch’ between the function store, which returns a pure value v, and the fetch argument of the task, which must return an f v for some f. To fix the mismatch, we wrap the result of store in the Identity monad: the function Identity . store has the type k → Identity v, and can now be passed to a task. The result comes as Maybe (Identity v), hence we now need to get rid of the Identity wrapper by applying runIdentity to the contents of Maybe.
In the GHCi session below we define a pure key/value store with A1 set to 10 and all other keys set to 20 and compute the values corresponding to keys A1 and B1 in the sprsh1 example:
λ> store key = if key == "A1" then 10 else 20 λ> compute sprsh1 store "A1" Nothing λ> compute sprsh1 store "B1" Just 30
As expected, we get Nothing for an input key A1 and Just 30 for B1.
Notice that, even though compute takes a Task Monad as its argument, its application to a Task Applicative typechecks just fine. It feels a bit like sub-typing, but is actually just ordinary higher-rank polymorphism.
Now let’s look at a function that can only be applied to applicative tasks.
Static dependencies
The formula A1 + A2 in the sprsh1 example statically depends on two keys: A1 and A2. Usually we would extract such static dependencies by looking at the syntax tree of the formula. But our Task abstraction has no such syntax tree. Yet, remarkably, we can use the polymorphism of a Task Applicative to find its dependencies. Here is the code:
dependencies :: Task Applicative k v -> k -> [k] dependencies task key = case task (\k -> Const [k]) key of Nothing -> [] Just (Const ks) -> ks
Here Const is the standard Haskell Const functor. We instantiate f to Const [k]. So a value of type f v, or in this case Const [k] v, contains no value v, but does contain a list of keys of type [k] which we use to record dependencies. The fetch callback that we pass to task records a single dependency, and the standard Applicative instance for Const combines the dependencies from different parts of the task. Running the task with f = Const [k] will thus accumulate a list of the task’s dependencies – and that is just what dependencies does:
λ> dependencies sprsh1 "A1" [] λ> dependencies sprsh1 "B1" ["A1", "A2"]
Notice that these calls to dependencies do no actual computation. They cannot: we are not supplying any input values. So, through the wonders of polymorphism, we are able to extract the dependencies of the spreadsheet formula, and to do so efficiently, simply by running its code in a different Applicative! This is not new, for example see this paper, but it is cool.
Dynamic dependencies
Some build tasks have dynamic dependencies, which are determined by values of intermediate computations. Such tasks correspond to the type Task Monad k v. Consider this spreadsheet example:
A1: 10 B1: IF(C1=1,B2,A2) C1: 1 A2: 20 B2: IF(C1=1,A1,B1)
Note that B1 and B2 statically form a dependency cycle, but Excel (which uses dynamic dependencies) is perfectly happy. The diagram below illustrates how cyclic dependencies are resolved when projecting them on conditions C1=1 and C1=2 (rectangles and rounded rectangles denote inputs and outputs, respectively). Incidentally, my PhD thesis was about a mathematical model for such conditional dependency graphs, which was later developed into an algebra of graphs.
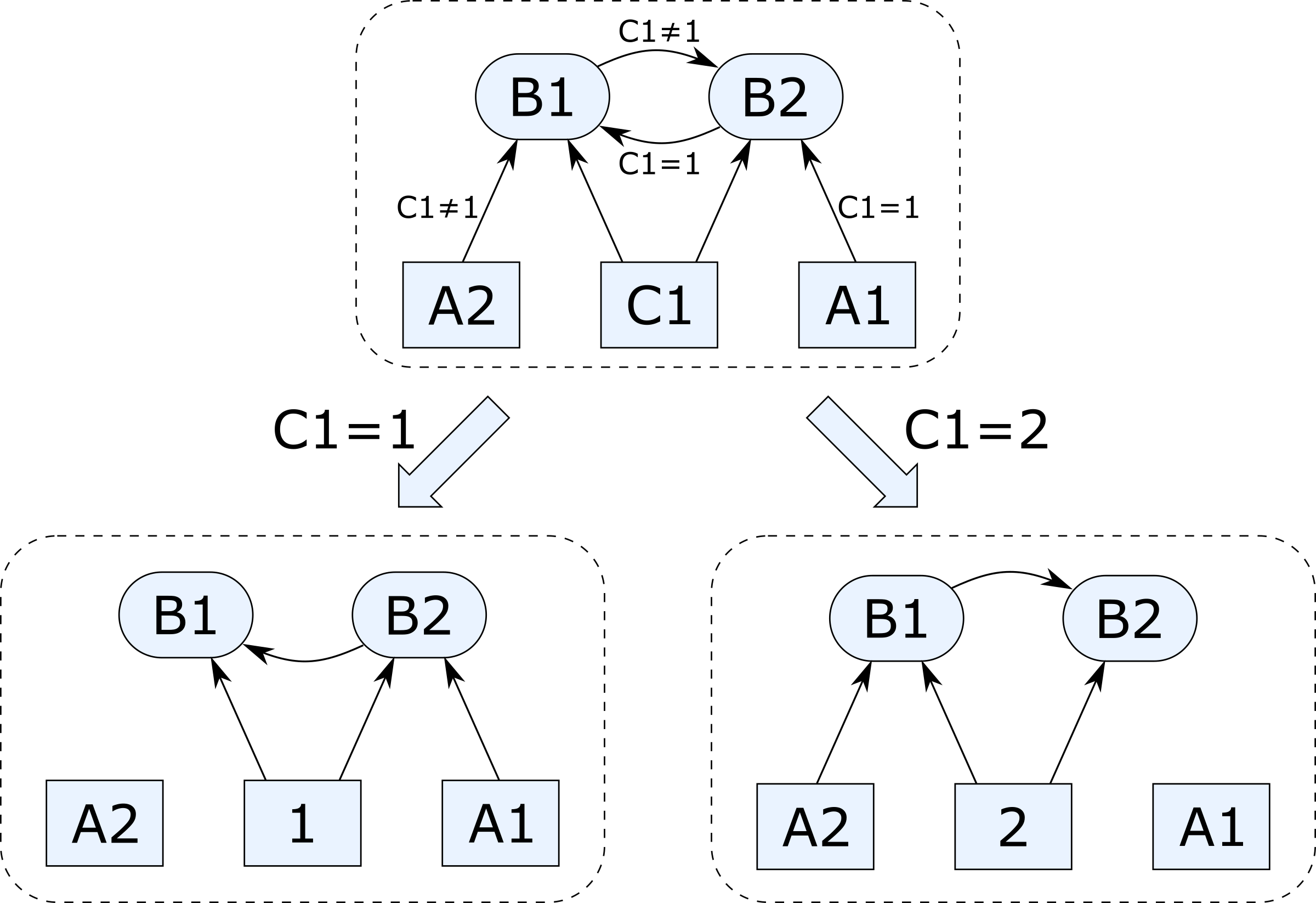
We can express this spreadsheet using our task abstraction as:
sprsh2 :: Task Monad String Integer sprsh2 fetch "B1" = Just $ do c1 <- fetch "C1" if c1 == 1 then fetch "B2" else fetch "A2" sprsh2 fetch "B2" = Just $ do c1 <- fetch "C1" if c1 == 1 then fetch "A1" else fetch "B1" sprsh2 _ _ = Nothing
The big difference compared to sprsh1 is that the computation now takes place in a Monad, which allows us to extract the value of C1 and fetch different keys depending on whether or not C1 = 1.
We cannot find dependencies of monadic tasks statically; notice that the application of the function dependencies to sprsh2 will not typecheck. We need to run a monadic task with concrete values that will determine the discovered dependencies. Thus, we introduce the function track: a combination of compute and dependencies that computes both the resulting value and the list of its dependencies in an arbitrary monadic context m:
track :: Monad m => Task Monad k v -> (k -> m v) -> k -> Maybe (m (v, [k])) track task fetch = fmap runWriterT . task trackingFetch where trackingFetch :: k -> WriterT [k] m v trackingFetch k = tell [k] >> lift (fetch k)
We use the standard(*) Haskell WriterT monad transformer to record additional information — a list of keys [k] — when computing a task in an arbitrary monad m. We substitute the given fetch with a trackingFetch that, in addition to fetching a value, tracks the corresponding key. The task returns the value of type Maybe (WriterT [k] m v), which we unwrap by applying runWriterT to the contents of Maybe. Below we give an example of tracking monadic tasks when m = IO:
λ> fetchIO k = do putStr (k ++ ": "); read <$> getLine λ> fromJust $ track sprsh2 fetchIO "B1" C1: 1 B2: 10 (10,["C1","B2"]) λ> fromJust $ track sprsh2 fetchIO "B1" C1: 2 A2: 20 (20,["C1","A2"])
As expected, the dependencies of cell B1 from sprsh2 are determined by the value of C1, which in this case is obtained by reading from the standard input via the fetchIO callback.
A simple build system
Given a task description, a target key, and a store, a build system returns a new store in which the values of the target key and all its dependencies are up to date. What does “up to date” mean? The paper answers that in a formal way.
The three functions described above (compute, dependencies and track) are sufficient for defining the correctness of build systems as well as for implementing a few existing build systems at a conceptual level. Below is an example of a very simple (but inefficient) build system:
busy :: Eq k => Task Monad k v -> k -> Store k v -> Store k v busy task key store = execState (fetch key) store where fetch :: k -> State (Store k v) v fetch k = case task fetch k of Nothing -> gets (getValue k) Just act -> do v <- act; modify (putValue k v); return v
Here Store k v is an abstract store datatype equipped with getValue and setValue functions. The busy build system defines the callback fetch so that, when given a target key, it brings the key up to date in the store, and returns its value. The function fetch runs in the standard Haskell State monad, initialised with the incoming store by execState. To bring a key k up to date, fetch asks the task description task how to compute k. If task returns Nothing the key is an input, so fetch simply reads the result from the store. Otherwise fetch runs the action act returned by the task to produce a resulting value v, records the new key/value mapping in the store, and returns v. Notice that fetch passes itself to task as an argument, so that the latter can use fetch to recursively find the values of k‘s dependencies.
Given an acyclic task description, the busy build system terminates with a correct result, but it is not a minimal build system: it doesn’t keep track of keys it has already built, and will therefore busily recompute the same keys again and again if they have multiple dependants. See the paper for implementations of much more efficient build systems.
For a few monads more
We have already used a few cool Haskell types — Identity, Const, WriterT and State — to manipulate our Task abstraction. Let’s meet a few other members of the cool-types family: Proxy, ReaderT, MaybeT and EitherT.
The Proxy data type allows us to check whether a key is an input without providing a fetch callback:
isInput :: Task Monad k v -> k -> Bool isInput task = isNothing . task (const Proxy)
This works similarly to the dependencies function, but in this case we do not even need to record any additional information, thus we can replace Const with Proxy.
One might wonder: if we do not need the fetch callback in case of input, can we rewrite our Task abstraction as follows?
type Task2 c k v = forall f. c f => k -> Maybe ((k -> f v) -> f v)
Yes, we can! This definition is isomorphic to Task. This isn’t immediately obvious, so below is a proof. I confess: it took me a while to find it.
toTask :: Task2 Monad k v -> Task Monad k v toTask task2 fetch key = ($fetch) <$> task2 key fromTask :: Task Monad k v -> Task2 Monad k v fromTask task key = runReaderT <$> task (\k -> ReaderT ($k)) key
The toTask conversion is relatively straightforward, but fromTask is not: it uses a ReaderT monad transformer to supply the fetch callback as the computation environment, extracting the final value with runReaderT.
Our task abstraction operates on pure values and has no mechanism for exception handling. It turns out that it is easy to turn any Task into a task that can handle arbitrary exceptions occurring in the fetch callback:
exceptional :: Task Monad k v -> Task Monad k (Either e v) exceptional task fetch = fmap runExceptT . task (ExceptT . fetch)
The exceptional task transformer simply hides exceptions of the given fetch of type k → f (Either e v) by using the standard ExceptT monad transformer, passes the resulting fetch callback of type k → ExceptT e f v to the original task, and propagates the exceptions by runExceptT. Using MaybeT, one can also implement a similar task transformer that turns a Task Monad k v into the its partial version Task Monad k (Maybe v).
Our final exercise is to extract all possible computation results of a non-deterministic task, e.g. B1 = A1 + RANDBETWEEN(1,2) that can be described as a Task Alternative:
sprsh3 :: Task Alternative String Integer sprsh3 fetch "B1" = Just $ (+) <$> fetch "A1" <*> (pure 1 <|> pure 2) sprsh3 _ _ = Nothing
We therefore introduce the function computeND that returns the list of all possible results of the task instead of just one value (‘ND’ stands for ‘non-deterministic’):
computeND :: Task MonadPlus k v -> (k -> v) -> k -> Maybe [v] computeND task store = task (return . store)
The implementation is almost straightforward: we choose f = [] reusing the standard MonadPlus instance for lists. Let’s give it a try:
λ> store key = if key == "A1" then 10 else 20 λ> computeND sprsh3 store "A1" Nothing λ> computeND sprsh3 store "B1" Just [11,12] λ> computeND sprsh1 store "B1" Just [30]
Notice that we can apply computeND to both non-deterministic (sprsh3) as well as deterministic (sprsh1) task descriptions.
Non-deterministic tasks are interesting because they allow one to try different algorithms to compute a value in parallel and grab the first available result — a good example is portfolio-based parallel SAT solvers. This shouldn’t be confused with a deterministic composition of tasks, which is also a useful operation, but does not involve any non-determinism:
compose :: Task Monad k v -> Task Monad k v -> Task Monad k v compose t1 t2 fetch key = t1 fetch key <|> t2 fetch key
Here we simply compose two task descriptions, picking the first one that knows how to compute a given key. Together with the trivial task that returns Nothing for all keys, this gives rise to the Task monoid.
Final remarks
We introduced the task abstraction to study build systems, but it seems to be linked to a few other topics, such as memoization, self-adjusting computation, lenses and profunctor optics, propagators and what not.
Have we just reinvented the wheel? It might seem so, especially if you look at these type signatures from the lens library:
type Lens s t a b = forall f. Functor f => (a -> f b) -> s -> f t type Traversal s t a b = forall f. Applicative f => (a -> f b) -> s -> f t
Our implementations of functions like dependencies are heavily inspired by — or to be more accurate — stolen from the lens library. Alas, we have been unable to remove the Maybe used to encode whether a key is an input, without complicating other aspects of our definition.
The task abstraction can be used to express pure functions in a way that is convenient for their memoization. Here is an example of encoding one of the most favourite functions of functional programmers:
fibonacci :: Task Applicative Integer Integer fibonacci fetch n | n >= 2 = Just $ (+) <$> fetch (n-1) <*> fetch (n-2) | otherwise = Nothing
Here the keys n < 2 are input parameters, and one can obtain the usual Fibonacci sequence by picking 0 and 1 for n = 0 and n = 1, respectively. Any minimal build system will compute the sequence with memoization, i.e. without recomputing the same value twice.
Interestingly, the Ackermann function — a famous example of a function that is not primitive recursive — can’t be expressed as a Task Applicative, since it needs to perform an intermediate recursive call to determine one of its dependencies:
ackermann :: Task Monad (Integer, Integer) Integer ackermann fetch (n, m) | m < 0 || n < 0 = Nothing | m == 0 = Just $ pure (n + 1) | n == 0 = Just $ fetch (m - 1, 1) | otherwise = Just $ do index <- fetch (m, n - 1) fetch (m - 1, index)
Now that we’ve seen examples of applicative and monadic tasks, let us finish with an example of a functorial task — the Collatz sequence:
collatz :: Task Functor Integer Integer collatz fetch n | n <= 0 = Nothing | otherwise = Just $ f <$> fetch (n - 1) where f k | even k = k `div` 2 | otherwise = 3 * k + 1
So here is a claim: given a Task, we can memoize, self-adjust, propagate and probably do any other conceivable computation on it simply by picking the right build system!
Update: how to handle failures
Sjoerd Visscher’s comment (below) pointed out that the fetch callback is defined to be total: it has type k → f v and returns a value for every key. It may be useful to allow it to fail for some keys. I know of three ways of modelling failure using the Task abstraction:
(1) Include failures into the type of values v, for example:
data Value = FileNotFound | FileContents ByteString
This is convenient if tasks are aware of failures. For example, a task may be able to cope with missing files, e.g. if fetch “username.txt” returns FileNotFound, the task could use the literal string “User” as a default value. In this case it will depend on the fact that the file username.txt is missing, and will need to be rebuilt if the user later creates this file.
In many cases this approach is isomorphic to choosing v = Either e v’.
(2) Include failures into the computation context f, for example:
cells :: Map String Integer cells = Map.fromList [("A1", 10), ("A2", 20)] fetch :: String -> Maybe Integer fetch k = Map.lookup k cells
We are choosing f = Maybe and thanks to the polymorphism of Task, any task can be executed in this context without any changes. For example, sprsh1 fetch “B1” now returns Just (Just 30), but sprsh1 fetch “B2” fails with Just Nothing.
This is convenient if tasks are not aware of failures, e.g. we can model Excel formulas as pure arithmetic functions, and introduce failures “for free” if/when needed by instantiating Task with an appropriate f. Also see the function exceptional defined above, which allows us to add arbitrary exceptions to a failure-free context f.
(3) Finally, the task itself might not want to encode failures into the type of values v, but instead demand that f has a built-in notion of failures. This can be done by choosing a suitable constraint c, such as Alternative, MonadPlus or even better something specific to failures e.g. MonadZero or MonadFail. Then both the callback and the task can reuse the same failure mechanism as shown below:
class Monad m => MonadFail m where fail :: String -> m a sprsh4 :: Task MonadFail String Integer sprsh4 fetch "B1" = Just $ do a1 <- fetch "A1" a2 <- fetch "A2" if a2 == 0 then fail "division by 0" else return (a1 `div` a2) sprsh4 _ _ = Nothing
Are there any other types of failure that are not covered above?
Footnotes
(*) Beware: as of writing, standard WriterT transformers have a space leak which may be an issue if a task has many dependencies. You might want to consider using a more efficient CPS-based WriterT transformer.
I wonder why you require from the callback to always return a value for any key? Wouldn’t it make more sense to allow it to fail too? Then you get:
type Task c k v = forall f. c f => (k -> Maybe (f v)) -> k -> Maybe (f v)
But you could also require that f has failure built in. Then Task Applicative becomes Task Alternative (with empty instead of Nothing) and Task Monad becomes Task MonadPlus (with mzero instead of Nothing) and Task becomes a proper optic:
type Task c k v = forall f. c f => (k -> f v) -> k -> f v
If your original f doesn’t support failure you can replace it with Compose Maybe f.
Thanks for your comment, Sjoerd! We’ve been thinking along similar lines, and perhaps the Task abstraction can still be improved by finding a better way to express various failures.
There are currently three ways of modelling callback failure using our Task abstraction:
(1) Include failures into the type of values v, for example:
data FileContents = FileNotFound | Contents ByteString
This is convenient when the task has a built-in notion of failures. For example, a build rule may be designed to cope with some missing files, e.g. if fetch “username.txt” returns FileNotFound, a build rule could use the literal string “User” as a default value. In this case it will depend on the fact that the file “username.txt” is missing, and will be rebuilt if the user later creates this file.
In many cases the result is isomorphic to choosing v = Maybe v’.
(2) Include failures into the context f, for example:
values :: Map String Integer
fetch :: String -> Maybe Integer
fetch k = Map.lookup k values
Now we are choosing f = Maybe.
This is convenient when the task itself has no built-in notion of failures, e.g. we can model Excel formulas as pure arithmetic functions, and introduce failures “for free” if/when needed by instantiating Task with an appropriate f.
(3) Finally, the task itself might not want to encode failures into the type of values v, but instead demand that f has a built-in mechanism for expressing failures. This can be done by choosing an appropriate c, e.g ApplicativeZero, MonadZero, Alternative, MonadPlus, etc.
Now, let’s look at the type you propose:
type Task c k v = forall f. c f => (k -> Maybe (f v)) -> k -> Maybe (f v)
Here the first Maybe is outside f, so a failure is known ‘statically’ by simply looking at the given key (similar to the above fetch example with Map.lookup). This will not work in cases when you need to perform some effects in order to determine if the lookup has failed, e.g. to check if the file is actually missing on disk. Here you want something like IO (Maybe v) instead, and I see no way of fitting this into the above type signature.
Your second type:
type Task c k v = forall f. c f => (k -> f v) -> k -> f v
is essentially the same as ours with respect to failures, but it doesn’t have a mechanism to (statically) indicate that a given key is an input. Are you suggesting to indicate this using the failure mechanism? While this works for some examples, I don’t think it’s sufficient in general: some of our build systems exploit the fact that it is possible to determine whether a key is an input statically, without performing an actual computation, i.e. they require the function isInput implemented above. After removing Maybe from the result, it becomes harder or impossible to implement isInput.
I think I should add the above explanation of three ways of modelling failure into the blog post.
I’ve added a section on failures to the blog post.
> This definition is isomorphic to Task. This isn’t immediately obvious, so below is a proof. I confess: it took me a while to find it.
When I read this I wondered if you could derive one from the other using the algebraic structure of ADTs (“algebra of algebraic data types”), to go from one to the other but of course that doesn’t work:
(1 + (fv ^ (fv ^ k))) ^ k
((1 + fv) ^ k) ^ (fv ^ k)
And I’m sure the existentially quantified term needs to be treated differently, but no idea how. In any case I would be really interested if there was some way to reason algebraically either to determine that there must exist some isomorphism to Task2, or to derive the implementation.
In poking at this I did notice a couple things that might not really be that interesting…
First, as you probably knew `toTask` doesn’t require any constraint, and this definition is a little more terse:
toTask :: Task2 Unconstrained k v -> Task Unconstrained k v
toTask = flip . fmap sequenceA
For a second I was excited thinking that we could have:
fromTask :: Task Unconstrained k v -> Task2 Unconstrained k v
fromTask = fmap sequenceA . flip
But that of course is impossible, since we can’t have Traversable ((->) a)
On a whim though a hayoo search turned up http://hackage.haskell.org/package/countable-1.0/docs/Data-Searchable.html#v:assemble
So I guess an alternative would have `(f v)` and `k` both be constrained to `Finite` but that’s probably not useful at all.
Hello Brandon! Many thanks for sharing your observations — they are very interesting and useful. As soon as my versions of toTask and fromTask successfully compiled I happily switched to other things and never looked back. But it’s interesting to see if we can find a more principled approach to finding such transformations — mine was: think really really hard and try out monad transformers until it works 🙂 Surely we can do better.
Also thanks a lot for the reference to `assemble` and `Finite`. This is something that might come in handy in my work on selective functors (https://blogs.ncl.ac.uk/andreymokhov/selective).