
Since beginning implementation of Newcastle University’s Research Publications and Copyright Policy in January 2023, the open research landscape has continued to transform. Library Research Services have been integrating our RPCP policy into open research publishing practices across the university. We have been doing this by supporting researchers and professional services staff while monitoring the uptake using our research support systems. Before we dive into the progress made over the past 9 months, we would first like to extend a thank you to our staff and students for recognising the benefits of the new policy and embracing change, and retaining their rights to publish their work where they see fit.
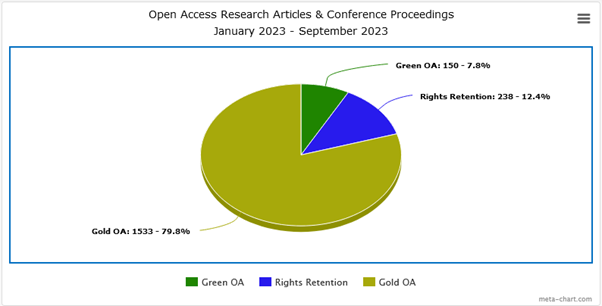
We have made 1,533* articles open access via the gold (paid) route and 388* available using the green (free) route. 238* of the publications made available through green open access were because of our policy with more research articles being accepted for publication containing the statement.
Implementing the policy required extensive planning and coordination. We developed a communications plan outlining the various media and methods we could use including channels, time frames and promotional material to convey the policy clearly and effectively. We added a web page within Library Research Services detailing the policy, a step-by-step guide for researchers and professional services staff and a list of FAQs to pre-empt and answer any questions or concerns they may have.
We are grateful to be part of the N8 Research Partnership which has allowed us to work together while launching similar policies around rights retention. The partnership enabled us to anticipate and tackle the issues we faced as a collective while allowing us to benchmark our progress with other research-intensive universities across the North of England. We liaised with our colleagues in Research, Strategy and Development to discuss how our policy aligned with our Ownership, Protection and Exploitation of Intellectual Property for Employees and the Open Access Policy Statement.
The first practical steps we took towards implementation was to contact over 150 publishers informing them of our policy. The publishers were based on a list from Edinburgh University and adapted to include those our researchers publish with. Once we were in possession of our letter, written and signed by Legal Services and N8 Rights Retention statement, we began contacting publishers as a courtesy.
The next stage involved informing our authors, we contacted each school asking to come along and present the policy to interested parties and we received a very welcoming response. The information was then fed through to various teams within the university by Professional Services staff. By speaking to staff directly, we were able to field questions and concerns to make incorporating the new policy as seamless as possible in the attempt to minimise the impact this would have on our academic’s workload. We set up Open Access Zoom Drop-In sessions to give the opportunity for researchers and members of staff to ask questions surrounding the policy, ask general open access queries and offer advice on good research practice.
As we develop and support open research while continuing to advocate for our research publications policy, the N8 have proposed a webinar for 23rd October 2023 at 10.15am (BST) to give the opportunity for those universities who launched their policies to present on their experience, the barriers they faced and offering advice to other institutions wishing to embark on their own rights retention journey. Details of how to sign up are posted in our Library Calendar.
*Figures taken from CRIS (MyImpact) (Jan 2023-Sep 2023)







