Previously, we showed the Prisoner’s contract and how it would force the two clouds to behave honestly, by creating a Prisoner’s Dilemma. However, this only works if the two clouds cannot make credible commitments. The fundamental problem in the Prisoner’s Dilemma and in game 1 (in the previous post) is that each player cannot believe the other, a selfish utility maximizer, will follow the collusion strategy.
Now if someone does not believe you, you cannot convince him/her by just talking. What convinces a rational player is by showing that lying will make you worse off. If lying is not in your interest, you will not lie. And if you want someone to do what you expected, you have to show doing so is in the best interest of him/her.
That is the idea behind the Colluder’s contract, in which both clouds show their loyalty to collusion (i.e. sending the agreed wrong result r) by promising that I will suffer a loss if I cheat, and any damage caused by my cheating behaviour to you will be compensated. The one who initiates the collusion can also give a slice of his own profit to the other as an additional incentive. The contract again is based on deposit:
- Each cloud pays a large enough deposit into Colluder’s contract;
- Anyone who does not follow the collusion strategy will lose its own deposit, which is transferred to the other cloud.
- The ringleader commits to giving a bribe if the other follows the collusion strategy.
This colluder’s contract, when in place, will change the game into:
 As you can see, now the equilibrium (bold path) for the two clouds is to collude and both follow the collusion strategy.
As you can see, now the equilibrium (bold path) for the two clouds is to collude and both follow the collusion strategy.
This is bad. After trying to prevent collusion using smart contracts, we found smart contracts actually can be used to enable collusion. And if the client tries to counter that by another contract, the clouds can have another contract to counter back. This is an endless loop.
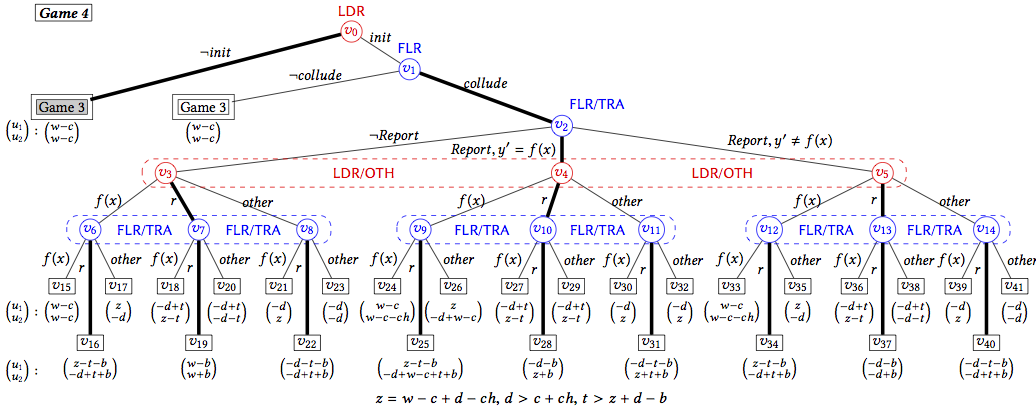
What can we do then, if we cannot counter directly back? In the end, we came up with the idea that uses a smart contract to incentivize secret betrayal and reporting. This leads to the Traitor’s contract. In this contract, the first cloud who reports collusion will not be punished by the prisoner’s contract and will get an additional reward if the collusion attempt does exist (there is a motivation to report). However, if someone tries to report a non-existent collusion case, it will have to bear the consequence and suffer a loss (there is a motivation not to abuse the system).
The consequence of reporting is that the client can call the trusted party, and find out who cheated. Once the trusted party is called, there is no point to counter back using another contract because the payoff of each cloud now only depends on whether it cheats or not, not the other’s behavior. So we break the loop. More importantly, the Traitor’s contract creates distrust between the clouds because “agree to collude then betray” is the best responding strategy if one cloud tries to initiate collusion. Now both clouds understand that, then no one will want to initiate collusion because they know they will be betrayed and end up with a worse payoff. Then both will behave honestly in the first place.
The contract works again by manipulating deposits paid upfront, by the client and the reporting cloud. Details can be found in the paper. Here I just show the full game tree:
 Implementation of the contracts in Solidity is available here. We actually tested the contracts on the official Ethereum network. There are challenges when implementing the contracts, one being that the transparency of a public blockchain. This means everything you put on the blockchain is visible to anyone. To make it worse, a blockchain is append-only, which means later there is no way to delete the data if you change your mind.
Implementation of the contracts in Solidity is available here. We actually tested the contracts on the official Ethereum network. There are challenges when implementing the contracts, one being that the transparency of a public blockchain. This means everything you put on the blockchain is visible to anyone. To make it worse, a blockchain is append-only, which means later there is no way to delete the data if you change your mind.
To preserve data privacy, we used some light cryptography, including Pedersen Commitment and Noninteractive zero-knowledge proof (NIZK). Pederson Commitment allows us to put a “commitment” (ciphertext) of a value on blockchain rather than the value itself. The commitment has the property that it leaks no information about the value it is committed to, and is bounded to that value in the sense that you cannot find a different value and convince other people that the new value was committed in the commitment. One problem caused by the “hiding” property is that the miners cannot see the values committed in the commitments and thus cannot compare them to determine whether the values are equal or not (which is needed to execute the contracts). Fortunately, we can use NIZKs, which are cryptographic proofs that can be checked publically with commitments as inputs. There are already NIZK protocols that allow proving equality/inequality of committed values, which we can simply use.
The cost of using the smart contracts comes from the transaction fees paid to the miners for storing and executing the contracts. In our experiments conducted on the official Ethereum network, the transaction fees are small. Depending on the transactions, the fees range from $0.01 to $0.40. This was done in May 2017, when the price of Ether was about $90. Today the Ether price is about $360, so transaction fees would be higher. Luckily, the most expensive operations are cryptographic ones, and the recent Ehtereum hard fork has made ECC cryptography (which we use) cheaper than before. So the increase in transaction fee should not be steep as the increase in Ether price.
The End.