The 52nd meeting of ISO/IEC SC 27 was held last week 11-15 April, in the beautiful city of Tampa, Florida State, USA. Many readers may not be familiar with ISO/IEC SC 27 and the security standards that it develops. So in this post I’ll provide a brief overview of SC 27, its organization structure and the process of taking a new technique to becoming part of the ISO/IEC SC 27 standards. Also, I’ll give a short account of some discussions occurred in Work Group 2 in which I am a member.
SC 27 is a technical subcommittee under ISO and IEC, with the specific mission to standardize security-related techniques. It is further divided into five working groups (WGs) with different working areas
- WG1: on information security management systems
- WG2: on cryptography and security mechanisms
- WG3: on security evaluation, testing and specification
- WG4: on security controls and services
- WG5: on identity management and privacy technologies
To standardize a new security technique, there are multiple stages to go through. A typical process is summarised as follows (also see ISO/IEC stage codes): Study Period (SP) -> Working Draft (WD) -> Committee Draft (CD) -> Draft International Standard (DIS) -> Final Draft International Standard (FDIS) -> Final publication. Exception FDIS, all other stages are compulsory. There are two ISO/IEC SC 27 meetings every year. In the six months between the meetings, national body experts are invited to provide comments on working documents received at each of the above stages. Comments are then discussed in the subsequent meeting, and hopefully are resolved to everyone’s satisfaction. If the document is considered stable (e.g., the comments received are mainly editorial changes, and technical comments are few and trivial) , the document can move on to the next stage, e.g., from the 1st Working Draft to the 1st CD; otherwise, it remains in the same stage with a new version of the document, i.e., the1st WD to the 2nd WD. The new document will be circulated among national body experts, with another cycle of discussing comments in the the next meeting. To standardize a new technique typically takes 3-4 years at least.
There are several criteria for deciding whether to include a new technique into the ISO/IEC standards. The first is the maturity of the technique. It’s generally expected that the proposed technique should have been published for a number of years (typically at least 4-5 years) in a stable state, and that it has received a sufficient level of cryptanalysis and no weakness has been found. The second is the industrial need — whether there is a practical demand for this technique to be standardized. Finally, it is considered desirable if the technique comes with security proofs. But “security proofs” can be a very tricky thing, as different people interpret what the “proof” should look like in different ways. Usually, the best security proof is still the proof of “time”, which is why the proposed technique should have been published for a number of years before it could be considered for standardization.
The ISO/IEC SC 27 standardization process may look dauntingly formal and lengthy, but once you get a grip of it, you will find it is actually easier than it looks. I started attending the ISO/IEC SC 27 meetings as a member of the UK national body delegation from April 2014 in the Hong Kong meeting, where I first presented J-PAKE to ISO/IEC SC 27 WG2 for inclusion into ISO/IEC 11770-4. The J-PAKE paper was first published at SPW’08 in April 2004. So it was 6 years old when I first presented it to ISO/IEC. We were open about the public analysis results of J-PAKE, and a full discussion track record was publicly viewable at the Cambridge Blog. My presentation was well received in the first meeting, with the agreement to start a study period and call for contributions from national bodies to comment on the possible inclusion of J-PAKE into ISO/IEC SC 27. Comments were discussed in the next Kuching meeting (Oct 2014) and it was unanimously agreed by national body delegates in that meeting to start the 1st working draft for the inclusion of J-PAKE into ISO/IEC 11770-4, with me and another member of WG 2 appointed as the editors. After two working drafts, the J-PAKE proposal was formally accepted by ISO/IEC SC 27 for inclusion in the Jaipur meeting (Oct 2015). This was the 1st CD stage. At this meeting, all comments received on the 1st CD of ISO/IEC 11770-4 were discussed and resolved. It was then agreed in this Tampa meeting that we would proceed to the DIS stage. It is expected that the final ISO/IEC 11770-4 standard that includes J-PAKE will be published in 2017. So it will take approximately 3 years in total.
Attending ISO/IEC SC 27 has been a great personal experience. It’s different from usual academic conferences in that the majority of attendees are from industry and they are keen to solve real-world security problems. Not many academics attend SC 27 though. One main reason is due to funding; attending two overseas meeting a year is quite a financial commitment. Fortunately, in the UK, all universities are starting to pay more attention to research impact (a new assessment category that was first introduced in the 2014 Research Excellence Framework). The research impact concerns the impact on industry and society (i.e., how the research actually benefits the society and changes the world rather than getting how many citations). I was fortunate and grateful that the CS faculty in my university decided to support my travels. Newcastle University CS did very well in REF 2014 and it was ranked the 1st in the UK for research impact. Hopefully it will continue to do well in the next REF. The development of an ISO/IEC standard for J-PAKE may help make a new impact case for REF 2020.
Tampa is a very beautiful city and it was such a long journey to get there. I would fail my university’s sponsorship if I stop here without sharing experience about other happenings in SC 27 Working Group 2.
In the Tampa meeting, one work item in WG 2 attracted a significant attention and heated debates. That item was about the NSA proposal to include SIMON and SPECK, two lightweight block ciphers designed by NSA, into the ISO/IEC 29192-2 standard.
Starting from the Mexico meeting in Oct 2014, the NSA delegate presented a proposal to include SIMON and SPEKE into the ISO/IEC 29192-2 standard. The two ciphers are designed to be lightweight, and are considered particularly suitable for Internet-of-Things (IoT) applications (e.g., ciphers used in light bulks, door locks etc). The proposal was discussed again in the subsequent Kuching meeting in April 2015, and a study period was initiated. The comments received during the study period were discussed in the subsequent Jaipur meeting in Oct 2015. There was a substantial disagreement among the delegates on whether to include SIMON and SPECK. In the end, it was decided to go for a straw poll by nation bodies (which rarely happened in WG 2). The outcome was a small majority (3 Yes, 2 No, all other countries abstained) to support the start of the first working draft, and meanwhile, continuing the study period and call for contributions to solicit more comments from national bodies. (However, the straw poll procedure at the Jaipur meeting was disputed to be invalid six months later in the Tampa meeting, as I’ll explain later.)
Comments on the 1st WD of SIMON and SPEKE were discussed in this Tampa meeting. Unsurprisingly, this, again, led to another long debate. The originally scheduled 45 minute session had to be stretched to nearly 2 hours. Most of the arguments were on technical aspects of the two ciphers. In summary, there were three main concerns.
First, the NSA proposal of SPECK includes a variant that has a block size of only 48 bits. This size was considered too small by crypto experts in WG 2. Some experts worry that a powerful attacker might perform pre-computation to identify optimal search paths. The pre-computation (2^48) is way beyond the capability of an ordinary attacker, but should be within the reach of a state-funded adversary. Also, the small block size makes key refreshing problematic. Due to the birthday paradox, a single key should not be used for encrypting more than 2^24 blocks, which is a rather small number. This bound is further reduced under the multi-user setting as some experts pointed out.
Second, the SIMON and SPECK ciphers were considered too young. The ciphers were first published in IACR eprint in June 2013 (yes, technical reports on IACR eprint are considered an acceptable form of publication according to ISO/IEC). When NSA first proposed them to ISO/IEC for standardization in the Mexico meeting (Oct 2014), the two ciphers were only 1 year and 4 months old. Both SIMON and SPECK are built on ARJ, which is a relatively new technique. The public understanding of security properties of ARJ is limited, as acknowledged by many experts in the meeting.
Third, the public analysis on SIMON and SPECK was not considered sufficient. The supporting argument from NSA in the Jaipur meeting (Oct 2015) was that the cryptanalysis results on SIMON and SPECK had “reached a a plateau”. However, within the next 6 months, there has been progress on the analysis, especially on SPECK (see the latest paper in 2016 due to Song et al). Hence, the argument of reaching a plateau is no longer valid. Instead, in the Tampa meeting, NSA argued that the cryptanalysis results became “more uniformly distributed” — i.e., now the safety margins for all SIMON and SPECK variants, as measured against the best known public analysis, are roughly centered around 30%, while 6 months ago, the safety margins for some SPECK variants were as high as 46%.
Most of the arguments in the meeting were technical, however, it was inevitable that the trustworthiness of the origin of SIMON and SPECK was called into question. There have been plenty of reports that allege the NSA involvement in inserting backdoors in security products and compromising security standards. The infamous random number generator algorithm, Dual_EC_DRBG, was once added into ISO/IEC 18031:2005 as proposed by NSA delegates, but later had to be removed when the news about the potential backdoor in Dual_EC_DRBG broke out. In this meeting, NSA delegates repeatedly reminded experts in WG 2 that they must judge the inclusion of a proposal based on the technical merits not where it came from. This was met with scepticism and distrust by some people.
Given the previous troubles with NSA proposals, some experts demanded that the designers of SIMON and SPECK should show security proofs, in particular, proofs that no backdoor exists. This request was reputed by the NSA delegate as technically impossible. One can point out the existence of a backdoor (if any), but proving the absence of it in a block cipher design is impossible. No block ciphers in the existing ISO/IEC standards have this kind of proofs, as the NSA delegate argued.
When all parties made their points, and the arguments became a circling repetition, it was clear that another straw poll was the only way out. This time, the straw poll was conducted among the experts in the room. On whether to support the SIMON and SPECK to proceed to the next (CD) stage, the outcome was an overwhelming objection (8 Yes, 16 No, the rest abstained).
Near the end of the Tampa meeting, it also merged that the straw poll in the previous Jaipur meeting on starting the 1st working draft for SIMON/SPECK was disputed to be invalid. According to the ISO/IEC directive, the straw poll should have been done among the experts present in the meeting rather than the national bodies. The difference is that in the latter there can only be one vote per country, while in the former, there can be many votes per country. In the Tampa meeting, it was suggested to redo the straw poll of the Jaipur meeting among experts, but the motion was rejected by NSA on the grounds that there were not enough experts in the room. This matter is being escalated to the upper management of ISO/IEC SC 27 for a resolution. At the time of writing this blog, this dispute remains still unresolved.
OK. That’s enough for the trip report. After a long and busy day of meetings, how to spend the rest of the day? A nice dinner with friends, and some beers, should be deserved.




 As you can see, now the equilibrium (bold path) for the two clouds is to collude and both follow the collusion strategy.
As you can see, now the equilibrium (bold path) for the two clouds is to collude and both follow the collusion strategy.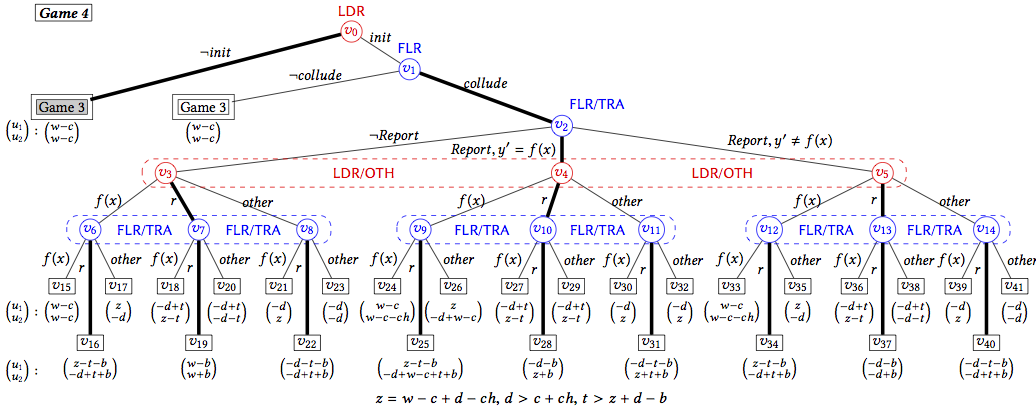 Implementation of the contracts in Solidity is available here. We actually tested the contracts on the official Ethereum network. There are challenges when implementing the contracts, one being that the transparency of a public blockchain. This means everything you put on the blockchain is visible to anyone. To make it worse, a blockchain is append-only, which means later there is no way to delete the data if you change your mind.
Implementation of the contracts in Solidity is available here. We actually tested the contracts on the official Ethereum network. There are challenges when implementing the contracts, one being that the transparency of a public blockchain. This means everything you put on the blockchain is visible to anyone. To make it worse, a blockchain is append-only, which means later there is no way to delete the data if you change your mind.







