 We start 2020 with our new VLE, Canvas, and a rich array of digital learning tools that can be used to support teaching. There are so many possibilities and it could easily be overwhelming.
We start 2020 with our new VLE, Canvas, and a rich array of digital learning tools that can be used to support teaching. There are so many possibilities and it could easily be overwhelming.
This is a short post to begin to answer one of the questions I hear last week “What 5 tools should I invest in?”.
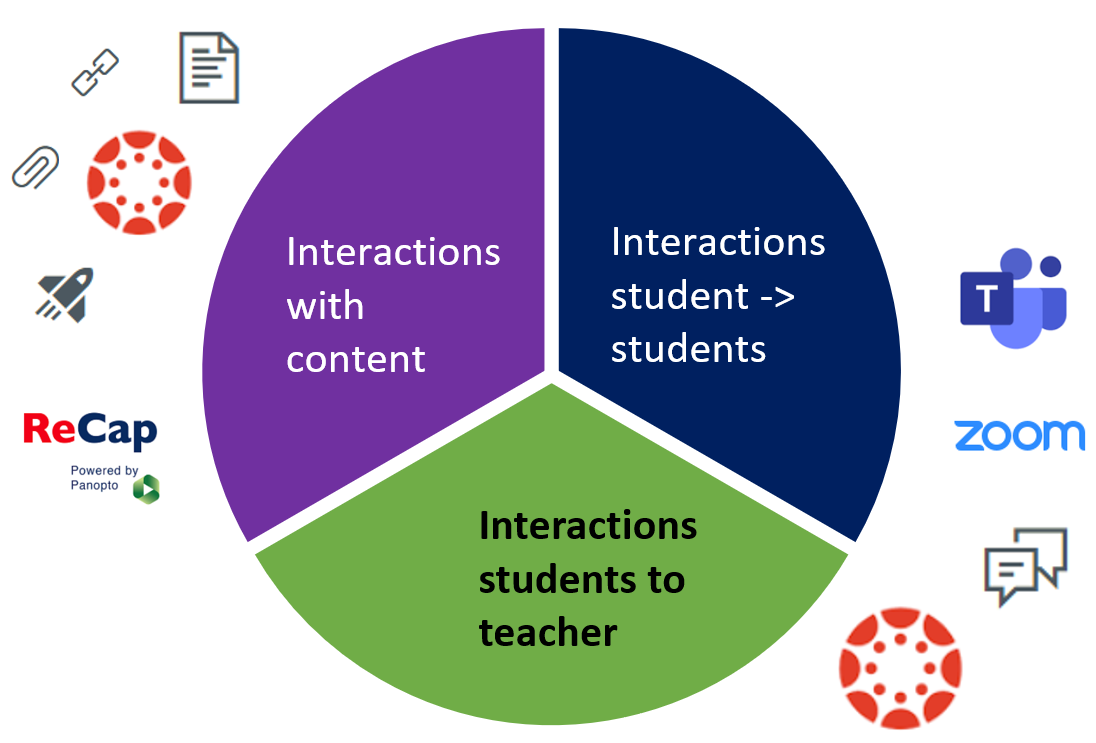
But, let’s back up a bit, before considering tools we need to think about what we want these tools to help us to achieve? Way back in 1998 Anderson and Garrison described the three more common types of interaction involving students:
- Student-content interactions
- Student-teacher interactions
- Student-student interactions
Let’s use this to come up with our list…
Student-content interactions
Your starting point here is Canvas itself. You can present information on pages, embed documents, link to resources on library reading list, include videos, audio and ReCap recordings.
Go to tool #1 has to be Canvas itself.
Linked to this is tool #2 Canvas quizzes.
Canvas support a wide range of question types: multiple choice, gap fill, short answer, matching, multiple answer. Quizzes can help students practice skills, check their learning and encourage them revisit material.
For short PowerPoint narrations the easiest place to start is the recording features that come as part of ReCap. We tend to think of ReCap as a lecture recording tool, but there is also a fabulous ReCap Personal Capture tool that you can use to record yourself, and publish in Canvas. There are several bonuses with using ReCap – you have the ability to do make simple edits, you can use automatic speech recognition to generate captions, and students have the ability pause, rewind and make notes on the recordings that you publish. ReCap personal capture comes in as tool #3 – you can install on your computer, or if you prefer you can use the new browser based recorder – Panopto Capture (beta).
Student to Teacher interactions
Outside the limited amount of PiP time you are likely to be meeting your students online. For synchronous meetings there is increasingly little to choose from between Zoom and Teams – the only significant factor being that Zoom permits people to connect by phone – so supports those on lower bandwidth.
Now is a great time to become confident with the online meeting tool you are planning on using throughout your module. I’ll leave it to you if #3 for you is Teams or Zoom – it would be sensible to settle on one, for you and your students. Teams could be a strong contender if you plan to use this as a collaboration space over the module/stage, in which case do review the article on Building an online community using Teams.
Once you setting on your meeting tool, now is a great time to explore options for using whiteboards, polling, breakout rooms in these spaces and to begin to plan active online sessions.
For tool #4 I’d go with Canvas Discussions – these are easy to use, work really well in the Canvas Student and Teacher apps and are great for Q&A sessions, introductions, crowd-sourcing activities, and of course discussions!
Student to Student interactions
Learning at university is a social! There are huge limitations on what we can do in person – but what can we do to help learning be as social as it can be? This isn’t so much about tools, but about the activities we design in: break out room discussions, group tasks, peer reviews, debates – things that might start in a timetabled session and then spill out.
For synchronous meetings and study sessions all our students have access to Zoom and Teams. We can model how to use these, build students’ confidence in these spaces and show them how they can collaborate in Microsoft 365 collaborative spaces (Word documents, OneNote…). I’ve already mentioned Teams and Zoom (#3), so for tool #5 I’ll pitch for Microsoft 365 with an emphasis on collaboration.
What do you think?
These are my top 5 tools, you may have a different list. What have I missed out?