Back in March we had performance issues with our firewalls. One of the things that our vendor raised was what they saw as an unusually high number of DNS queries to external servers. We were seeing around 2-3000 requests/second from our caching DNS servers to the outside world.
A bit more monitoring (encouraged by other sites reporting significantly lower rates than us) identified a couple of sources of unusual load:
1. The solution we use for filtering incoming mail sends DNS queries to all servers listed in resolv.conf in parallel. That doesn’t give any benefit in our environment so we changed things so that it only uses the caching DNS server on localhost.
2. We were seeing high rates of reverse lookups for IP addresses in ranges belonging to Google (and others) which are getting SERVFAIL responses. These are uncacheable so always result in queries to external servers. To test this theory I installed dummy empty reverse zones on the caching name servers and the queries immediately dried up. The fake empty zones meant that the local servers would return a cacheable NXDOMAIN rather than SERVFAIL.
An example of a query that results in SERVFAIL is www.google.my. [should be www.google.com.my]). That was being requested half a dozen times a second through one of our DNS servers. www.google.my just caught my eye – there are probably many others generating a similar rate.
Asking colleagues at other institutions via the ucisa-ig list and on ServerFault reinforced the hypothesis that (a) the main DNS servers were doing the right thing and (b) this was a local config problem (because no-one else was seeing this).
Turned on request logging on the BIND DNS servers and used the usual grep/awk/sort pipeline to summarise – that showed that most requests were coming from the Windows domain controllers.
Armed with this information we looked at the config on the Windows servers again and the cause was obvious. It was a very long-standing misconfiguration of the DNS server on the domain controllers – they were set to forward not only to a pair of caching servers running Bind (as I thought) but also all the other domain controllers which would in turn forward the request to the same set of servers. I’m surprised that this hadn’t been worse/shown up before since as long as the domain returns SERVFAIL the requests just keep circulating round.
The graph below shows the rate of requests that gave a SERVFAIL response – note the sharp decrease in March when we made the change to the DNS config on the AD servers. [in a fit of tidiness I deleted the original image file and now don’t have the stats to recreate it – the replacement doesn’t cover the same period]
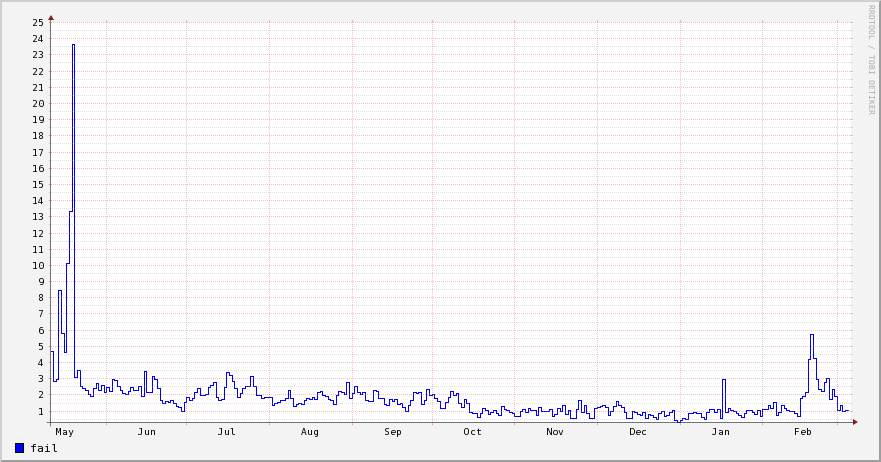
I can see why this might have seemed like a sensible configuration at the time – it looks (at one level) similar to the idea of a set of squid proxies asking their peers it they already have a resource cached). Queries that didn’t result in SERVFAIL were fine (so the obvious tests wouldn’t show any problems).
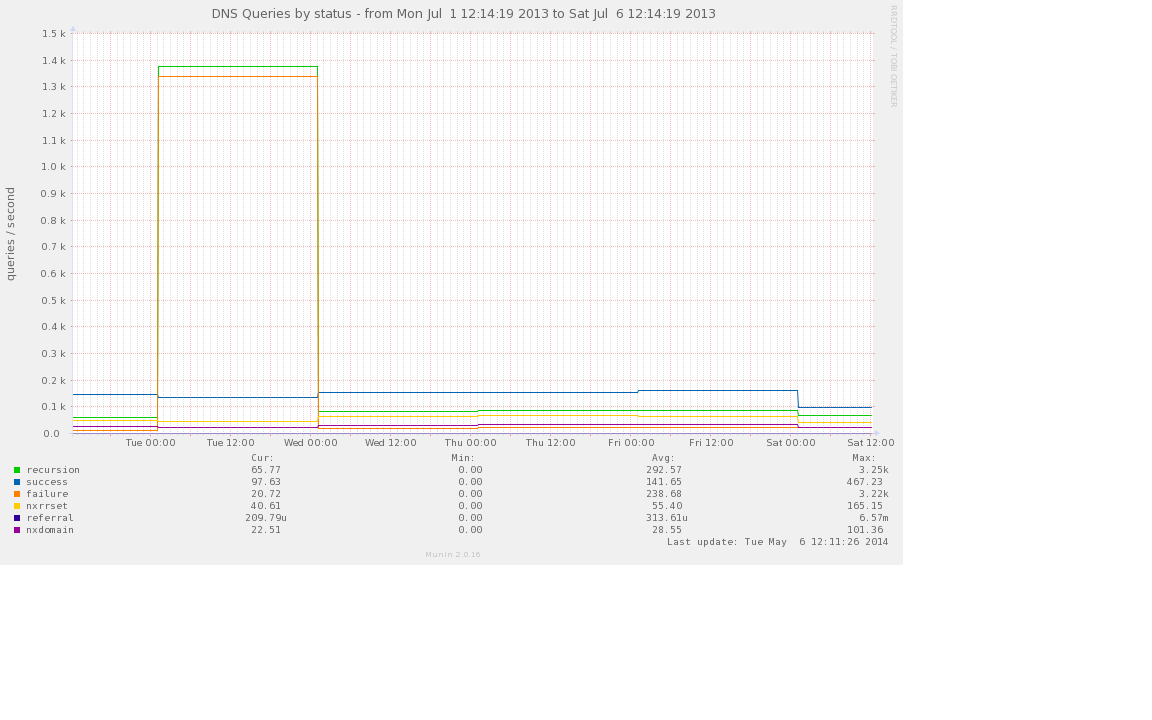
Postscript: I realised this morning that we’d almost certainly seen symptoms of this problem early last July – graph below shows the very sharp increase in requests followed by the sharp decrease when we installed some fake empty zones. This high level of requests was provoked by an unknown client on campus looking up random hosts in three domains which were all returning SERVFAIL. Sadly we didn’t identify the DC misconfiguration at the time.